게임 중 배달 음식이 도착하면 게임을 일시 중지한 후 배달 음식을 받고 자리로 돌아와 게임을 이어할 수 있음 → 인터럽트 처리 과정
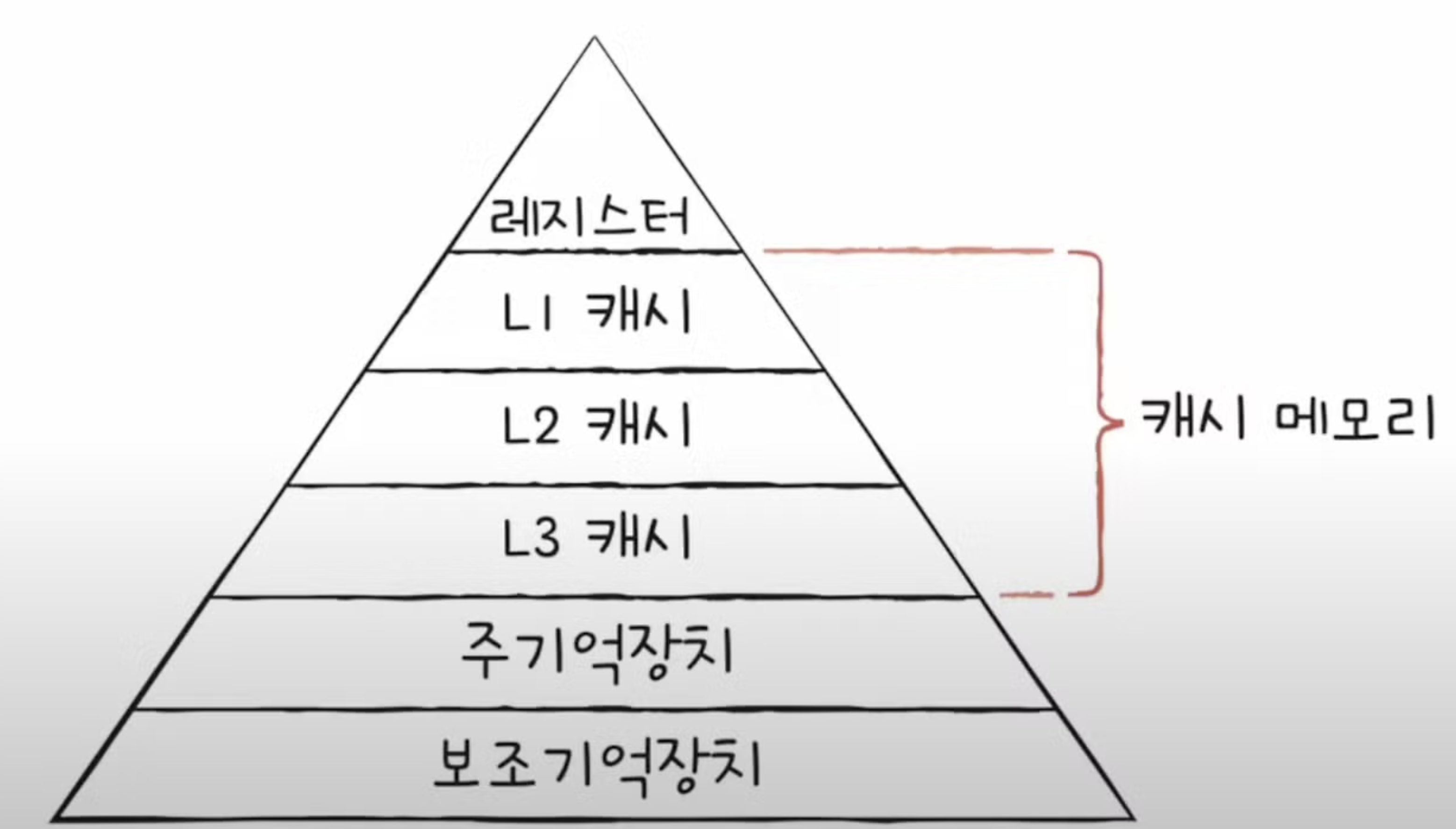
컴퓨터 시스템에서 기초적인 인터럽트 처리 구조
CPU가 특정 프로세스(프로세스 A)의 기계 명령어를 실행할 때 새로운 이벤트가 발생
네트워크 카드에 새로운 데이터가 들어오면 외부 장치가 인터럽트 신호를 보내고
CPU는 실행 중인 현재 작업의 우선순위가 인터럽트 요청보다 높은지 판단
인터럽트의 우선순위가 더 높다면 현재 작업 실행으 일시 중지하고 인터럽트를 처리하고 다시 현재 작업으로 돌아옴
프로그램은 계속 끊임없이 실행되는 것이 아니라 언제든지 장치에 의해 실행이 중단될 수 있음
하지만 이 과정은 프로그래머에게 드러나지 않으며 중단 없이 실행되고 있는 것처럼 느끼게 만듦
6.1.6. 인터럽트 구동식 입출력
인터럽트 발생 시 CPU가 실행하는 명령어 흐름
프로그램 A의 기계 명령어 n 실행
프로그램 A의 기계 명령어 n + 1 실행
프로그램 A의 기계 명령어 n + 2 실행
프로그램 A의 기계 명령어 n + 3 실행
인터럽트 신호 감지
프로그램 A의 실행 상태 저장
인터럽트 처리 기계 명령어 m 실행
인터럽트 처리 기계 명령어 m + 1 실행
인터럽트 처리 기계 명령어 m + 2 실행
인터럽트 처리 기계 명령어 m + 3 실행
프로그램 A의 실행 상태 복원
프로그램 A의 기계 명령어 n + 4 실행
프로그램 A의 기계 명령어 n + 5 실행
프로그램 A의 기계 명령어 n + 6 실행
프로그램 A의 기계 명령어 n + 7 실행
폴링 방식보다 효율적으로 시간을 낭비하지 않음
실제는 약간의 시간을 낭비하는데 주로 프로그램 A의 실행 상태를 저장하고 복원하는데 사용
프로그램 A의 관점에서 CPU가 실행하는 명령어 흐름은 아래와 같음
프로그램 A의 기계 명령어 n 실행
프로그램 A의 기계 명령어 n + 1 실행
프로그램 A의 기계 명령어 n + 2 실행
프로그램 A의 기계 명령어 n + 3 실행
프로그램 A의 기계 명령어 n + 4 실행
프로그램 A의 기계 명령어 n + 5 실행
프로그램 A의 기계 명령어 n + 6 실행
프로그램 A의 기계 명령어 n + 7 실행
CPU는 마치 중단된 적이 없는 것처럼 자신의 명령어를 계속 실행 → 프로그램 A의 실행 상태를 저장하고 복원하는 작업이 필요한 이유로 입출력을 비동기로 처리하는 방법을 인터럽트 구동식 입출력이라고 함 (interrupt driven input and output)
6.1.7 CPU는 어떻게 인터럽트 신호를 감지할까?
CPU가 기계 명령어를 실행하는 과정
명령어 인출(instruction fetch)
명령어 해독(instruction decode)
실행(execute)
다시 쓰기(write back)
CPU가 하드웨어의 인터럽트 신호를 감지하는 단계
인터럽트 신호가 발생하면 이 이벤트를 처리할지 여부를 반드시 결정해야 함
6.1.8 인터럽트 처리와 함수 호출의 차이
함수를 호출하기 이전에 반환 주소, 일부 범용 레지스터의 값, 매개변수 등 정보 저장이 필요
인터럽트 처리 점프는 서로 다른 두 실행 흐름을 포함하므로 함수 호출에 비해 저장해야 할 정보가 훨씬 많음
6.1.9 중단된 프로그램의 실행 상태 저장과 복원
프로그램 A가 실행 중일 때 인터럽트가 발생하면 A의 실행은 중단되고, CPU는 인터럽트 처리 프로그램(interrupt handler) B로 점프
CPU가 인터럽트 처리 프로그램 B를 실행할 때 다시 인터럽트가 발생하면 B는 중단되고 CPU는 인터럽트 처리 프로그램 C로 점프
CPU가 인터럽트 처리 프로그램 C를 실행할 때 도 다시 인터럽트가 발생하면 C의 실행은 중단되고 CPU는 인터럽트 처리 프로그램 D로 점프
D의 실행이 완료되면 프로그램 C, B, A 순서대로 반환됨
상태 저장 순서
프로그램 A의 상태 저장
프로그램 B의 상태 저장
프로그램 C의 상태 저장
상태 복원 순서
프로그램 C의 상태 복원
프로그램 B의 상태 복원
프로그램 A의 상태 복원
상태가 먼저 저장될수록 상태 복원은 더 나중에 됨 → 스택를 사용해 구현하고, 스택에는 다음 기계 명령어 주소와 프로그램의 상태가 저장됨
현재의 문자를 나타내는 value, 다음에 나올 문자를 나타내는 next_ 배열을 가지고 있음
linked list나 tree 형태와 비슷
from typing import List
from dataclasses import dataclass, field
R = 26
@dataclass
class RTrieNode:
size = R
value: int
next_: List["RTrieNode"] = field(default_factory=lambda: [None] * R)
def __post_init__(self):
if len(self.next_) != self.size:
raise ValueError(f"리스트(next_)의 길이가 유효하지 않음")
size는 class variable로 모든 객체가 값을 공유
value는 정수형이지만 기본값이 없으므로 객체 생성시 반드시 값을 정해줘야 함
next_는 R크기 만큼의 길이를 가진 list로 초기화
__post_init__은 next_가 원하는 형태로 잘 생성되었는지 확인하는 검증
from typing import List
from dataclasses import dataclass, field
R = 26 # 영어 알파벳
@dataclass
class RTrieNode:
size = R
value: int
next_: List["RTrieNode"] = field(default_factory=list)
def __post_init__(self):
if len(self.next_) != self.size:
raise ValueError(f"리스트(next_)의 길이가 유효하지 않음")
rt_node = RTrieNode(value=0) # ValueError: 리스트(next_)의 길이가 유효하지 않음
이터러블 객체
__iter__ 매직 메소드를 구현한 객체
파이썬의 반복은 이터러블 프로토콜이라는 자체 프로토콜을 사용해 동작
for e in my_object
위 형태로 객체를 반복할 수 있는지 확인하기 위해 파이썬은 고수준에서 아래 두가지 차례로 검사
객체가 __next__나 __iter__ 메서드 중 하나를 포함하는지 여부
객체가 시퀀스이고 __len__과 __getitem__을 모두 가졌는지 여부
For-loop에 대한 구체적인 과정
my_list = ["사과", "딸기", "바나나"]
for i in my_list:
print(i)
for 문이 시작할 때 my_list의 __iter__()로 iterator를 생성
내부적으로 i = __next__() 호출
StopIteration 예외가 발생하면 반복문 종료
Iterable과 Iterator의 차이
Iterable: loop에서 반복될 수 있는 python 객체, __iter__() 가 구현되어있어야 함
Iterator: iterable 객체에서 __iter__() 호출로 생성된 객체로 __iter__()와 __next__()가 있어야하고, iteration 시 현재의 순서를 가지고 있어야 함
이터러블 객체 만들기
객체 반복 시 iter() 함수를 호출하고 이 함수는 해당 객체에 __iter__ 메소드가 있는지 확인
from datetime import timedelta
from datetime import date
class DateRangeIterable:
"""자체 이터레이터 메서드를 가지고 있는 iterable"""
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._present_day = start_date
def __iter__(self):
return self # 객체 자신이 iterable 임을 나타냄
def __next__(self):
if self._present_day >= self.end_date:
raise StopIteration()
today = self._present_day
self._present_day += timedelta(days=1)
return today
for day in DateRangeIterable(date(2024, 6, 1), date(2024, 6, 4)):
print(day)
2024-06-01 2024-06-02 2024-06-03
for 루프에서 python은 객체의 iter() 함수를 호출하고 이 함수는 __iter__ 매직 메소드를 호출
self를 반환하면서 객체 자신이 iterable임을 나타냄
루프의 각 단계에서마다 자신의 next() 함수를 호출
next 함수는 다시 __next__ 메소드에게 위임하여 요소를 어떻게 생산하고 하나씩 반환할 것인지 결정
더 이상 생산할 것이 없는 경우 파이썬에게 StopIteration 예외를 발생시켜 알려줘야함
⇒ for 루프가 작동하는 원리는 StopIteration 예외가 발생할 때까지 next()를 호출하는 것과 같다
from datetime import timedelta
from datetime import date
class DateRangeIterable:
"""자체 이터레이터 메서드를 가지고 있는 이터러블"""
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._present_day = start_date
def __iter__(self):
return self
def __next__(self):
if self._present_day >= self.end_date:
raise StopIteration()
today = self._present_day
self._present_day += timedelta(days=1)
return today
r = DateRangeIterable(date(2024, 6, 1), date(2024, 6, 4))
print(next(r)) # 2024-06-01
print(next(r)) # 2024-06-02
print(next(r)) # 2024-06-03
print(next(r)) # raise StopIteration()
위 예제는 잘 동작하지만 하나의 작은 문제가 있음
max 함수 설명
iterable한 object를 받아서 그 중 최댓값을 반환하는 내장함수이다
숫자형뿐만 아니라 문자열 또한 비교 가능
str1 = 'asdzCda'
print(max(str1)) # z
str2 = ['abc', 'abd']
print(max(str2)) # abd 유니코드가 큰 값
str3 = ['2022-01-01', '2022-01-02']
print(max(str3)) # 2022-01-02
# 숫자로 이루어진 문자열을 비교할 때 각 문자열의 앞 부분을 비교해서 숫자가 큰 것을 출력
with 문이 없고 함수를 호출하면 offline_backup 함수가 context manager 안에서 자동으로 실행됨
원본 함수를 래핑하는 데코레이터 형태로 사용
단점은 완전히 독립적이라 데코레이터는 함수에 대해 아무것도 모름 (사실 좋은 특성)
contextlib 의 추가적인 기능
import contextlib
with contextlib.suppress(DataConversionException):
parse_data(nput_json_or_dict)
안전하다고 확신되는 경우 해당 예외를 무시하는 기능
DataConversionException이라고 표현된 예외가 발생하는 경우 parse_data 함수를 실행
컴프리헨션과 할당 표현식
코드를 간결하게 작성할 수 있고 가독성이 높아짐
def run_calculation(i):
return i
numbers = []
for i in range(10):
numbers.append(run_calculation(i))
print(numbers) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
위의 코드를 아래와 같이 바로 리스트 컴프리헨션으로 만들 수 있음
numbers = [run_calculation(i) for i in range(10)]
list.append를 반복적으로 호출하는 대신 단일 파이썬 명령어를 호출하므로 일반적으로 더 나은 성능을 보임
dis 패키지를 이용한 어셈블리코드 비교각 assembly 코드 (list comprehension)
import dis
def run_calculation(i):
return i
def list_comprehension():
numbers = [run_calculation(i) for i in range(10)]
return numbers
# Disassemble the list comprehension function
dis.dis(list_comprehension)
def for_loop():
numbers = []
for i in range(10):
numbers.append(run_calculation(i))
return numbers
# Disassemble the for loop function
dis.dis(for_loop)
import re
from typing import Iterable, Set
# Define the regex pattern for matching the ARN format
ARN_REGEX = r"arn:(?P<partition>[^:]+):(?P<service>[^:]+):(?P<region>[^:]*):(?P<account_id>[^:]+):(?P<resource_id>[^:]+)"
def collect_account_ids_from_arns(arns: Iterable[str]) -> Set[str]:
"""
arn:partition:service:region:account-id:resource-id 형태의 ARN들이 주어진 경우 account-id를 찾아서 반환
"""
collected_account_ids = set()
for arn in arns:
matched = re.match(ARN_REGEX, arn)
if matched is not None:
account_id = matched.groupdict()["account_id"]
collected_account_ids.add(account_id)
return collected_account_ids
# Example usage
arns = [
"arn:aws:iam::123456789012:user/David",
"arn:aws:iam::987654321098:role/Admin",
"arn:aws:iam::123456789012:group/Developers",
]
unique_account_ids = collect_account_ids_from_arns(arns)
print(unique_account_ids)
# {'123456789012', '987654321098'}
위 코드 중 collect_account_ids_from_arns 함수를 집중해서 보면,
def collect_account_ids_from_arns(arns: Iterable[str]) -> Set[str]:
"""
arn:partition:service:region:account-id:resource-id 형태의 ARN들이 주어진 경우 account-id를 찾아서 반환
"""
collected_account_ids = set()
for arn in arns:
matched = re.match(ARN_REGEX, arn)
if matched is not None:
account_id = matched.groupdict()["account_id"]
collected_account_ids.add(account_id)
return collected_account_ids
위 코드를 컴프리헨션을 이용해 간단히 작성 가능
def collect_account_ids_from_arns(arns: Iterable[str]) -> Set[str]:
"""
arn:partition:service:region:account-id:resource-id 형태의 ARN들이 주어진 경우 account-id를 찾아서 반환
"""
matched_arns = filter(None, (re.match(ARN_REGEX, arn) for arn in arns))
return {m.groupdict()["account_id"] for m in matched_arns}
python 3.8이후에는 할당표현식을 이용해 한문장으로 다시 작성 가능
def collect_account_ids_from_arns(arns: Iterable[str]) -> Set[str]:
"""
arn:partition:service:region:account-id:resource-id 형태의 ARN들이 주어진 경우 account-id를 찾아서 반환
"""
return {
matched.groupdict()["account_id"]
for arn in arns
if (matched := re.match(ARN_REGEX, arn)) is not None
}
정규식 이용한 match 결과들 중 None이 아닌 것들만 matched 변수에 저장되고 이를 다시 사용
더 간결한 코드가 항상 더 나은 코드를 의미하는 것은 아니지만 분명 두번째나 세번째 코드가 첫번째 코드보다는 낫다는 점에서는 의심의 여지가 없음
이는 여러번 확장되는 클래스의 메소드 이름을 충돌없이 오버라이드 하기 위해 만들어진거로 pythonic code의 예가 아님
결론
⇒ 속성을 private으로 정의하는 경우 하나의 밑줄 사용
프로퍼티(Property)
class Coordinate:
def __init__(self, lat: float, long: float) -> None:
self._latitude = self._longitude = None
self.latitude = lat
self.longitude = long
@property
def latitude(self) -> float:
return self._latitude
@latitude.setter
def latitude(self, lat_value: float) -> None:
print("here")
if lat_value not in range(-90, 90+1):
raise ValueError(f"유호하지 않은 위도 값: {lat_value}")
self._latitude = lat_value
@property
def longitude(self) -> float:
return self._longitude
@longitude.setter
def longitude(self, long_value: float) -> None:
if long_value not in range(-180, 180+1):
raise ValueError(f"유효하지 않은 경도 값: {long_value}")
self._longitude = long_value
coord = Coordinate(10, 10)
print(coord.latitude)
coord.latitude = 190 # ValueError: 유호하지 않은 위도 값: 190
property 데코레이터는 무언가에 응답하기 위한 쿼리
setter는 무언가를 하기 위한 커맨드
둘을 분리하는 것이 명령-쿼리 분리 원칙을 따르는 좋은 방법
보다 간결한 구문으로 클래스 만들기
객체의 값을 초기화하는 일반적인 보일러플레이트
보일러 플레이트: 모든 프로젝트에서 반복해서 사용하는 코드
def __init__(self, x, y, ...):
self.x = x
self.y = y
파이썬 3.7부터는 dataclasses 모듈을 사용하여 위 코드를 훨씬 단순화할 수 있다 (PEP-557)
@dataclass 데코레이터를 제공
클래스에 적용하면 모든 클래스의 속성에 대해서 마치 __init__ 메소드에서 정의한 것처럼 인스턴스 속성으로 처리
@dataclass 데코레이터가 __init__ 메소드를 자동 생성
field라는 객체 제공해서 해당 속성에 특별한 특징이 있음을 표시
속성 중 하나가 list처럼 변경가능한 mutable 데이터 타입인 경우 __init__에서 비어 있는 리스트를 할당할 수 없고 대신에 None으로 초기화한 다음에 인스턴스마다 적절한 값으로 다시 초기화 해야함
from dataclasses import dataclass
@dataclass
class Foo:
bar: list = []
# ValueError: mutable default <class 'list'> for field a is not allowed: use default_factory
안되는 이유는 위의 bar 변수가 class variable이라 모든 Foo 객체들 사이에서 공유되기 때문
class C:
x = [] # class variable
def add(self, element):
self.x.append(element)
c1 = C()
c2 = C()
c1.add(1)
c2.add(2)
print(c1.x) # [1, 2]
print(c2.x) # [1, 2]
아래처럼 default_factory 파라미터에 list 를 전달하여 초기값을 지정할 수 있도록 하면 됨
from dataclasses import dataclass, field
@dataclass
class Foo:
bar = field(default_factory=list)
Return a proxy object that delegates method calls to a parent or sibling class of type. This is useful for accessing inherited methods that have been overridden in a class.
공식문서 설명은 늘 어려움.
쉽게 말해, 부모나 형제 클래스의 임시 객체를 반환하고, 반환된 객체를 이용해 슈퍼 클래스의 메소드를 사용할 수 있음.
Cube가 아닌 Square기 때문에 super(Square, self)의 반환은 Square 클래스의 부모 클래스인 Rectangle 클래스의 임시 객체
결과적으로 Rectangle 인스턴스에서 area() 메소드를 찾음
Q. Square 클래스에 area 메소드를 구현하면??
그래도 super(Square, self) 가 Rectangle 클래스를 반환하기 때문에 Rectangle 인스턴스에서 area() 메소드를 호출
## super 클래스의 정의
class super(object):
def __init__(self, type1=None, type2=None): # known special case of super.__init__
"""
super() -> same as super(__class__, <first argument>)
super(type) -> unbound super object
**super(type, obj) -> bound super object; requires isinstance(obj, type)
super(type, type2) -> bound super object; requires issubclass(type2, type)**
Typical use to call a cooperative superclass method:
class C(B):
def meth(self, arg):
super().meth(arg)
This works for class methods too:
class C(B):
@classmethod
def cmeth(cls, arg):
super().cmeth(arg)
"""
# (copied from class doc)
두번째 argument : 첫번째 argument의 클래스 인스턴스를 넣어주거나 subclass를 넣어줘야함