반응형
컴파일러
- 목적: 통역사처럼 한 언어를 다른 언어로 변환하는 것
- 통역을 하려면 출발어(source language)와 도착어(target language)의 문법 구조를 알아야 함
컴파일러의 선택기준: 이식성
- 저수준 기계어: C/C++, Go, 파스칼은 바이너리 실행파일로 컴파일하는데 이는 컴파일한 플랫폼과 동일한 플랫폼에서만 사용할 수 있음
- 중간 언어: java, 닷넷 CLR은 여러 시스템 아키텍처에서 사용할 수 있는 중간언어로 컴파일 해서 가상머신에서 실행될 수 있음
- 파이썬 애플리케이션은 보통 소스 코드 형태로 배포됨
- 파이썬 인터프리터는 소스 코드를 변환한 후 한 줄씩 실행
- CPython 런타임이 첫 번째 실행될 때 코드를 컴파일하지만 이 단계는 일반 사용자에게 노출되지 않음
- 파이썬 코드는 기계어 대신 바이트코드라는 저수준 중간 언어로 컴파일되고 바이트코드는 .pyc 파일에 저장됨(캐싱)
- 코드를 변경하지 않고 같은 파이썬 애플리케이션을 다시 실행하면 매번 다시 컴파일하지 않고 컴파일된 바이트 코드를 불러오기 때문에 더 빠르게 실행
4.1 CPython이 파이썬이 아니라 C로 작성된 이유
- 컴파일러가 작동하는 방식 때문
컴파일러가 작동하는 방식 유형
- 셀프 호스팅 컴파일러: 자기 자신으로 작성한 컴파일러로 부트스트래핑이라는 단계를 통해서 만들어짐
- Go: C로 작성된 첫 번째 Go 컴파일러가 Go를 컴파일할 수 있게 되자 컴파일러를 Go 언어로 재 작성
- PyPy: 파이썬으로 작성된 파이썬 컴파일러
- source to source 컴파일러: 컴파일러를 이미 가지고 있는 다른 언어로 작성한 컴파일러
- Cpython : C를 사용하여 Python 컴파일
- ssl 이나 sockets 같은 표준 라이브러리 모듈이 저수준 운영체제 API에 접근하기 위해 C로 작성됨
4.2 파이썬 언어 사양
- 컴파일러가 언어를 실행하려면 문법 구조에 대한 엄격한 규칙이 필요
- CPython 소스 코드에 포함된 언어 사양은 모든 파이썬 인터프리터 구현이 사용하는 레퍼런스 사양
- 사람이 읽을 수 있는 형식 + 기계가 읽을 수 있는 형식으로 제공
- 문법 형식과 각 문법 요소가 실행되는 방식을 자세히 설명
4.2.1 파이썬 언어 레퍼런스
- 파이썬 언어의 기능을 설명하는 reStructuredText(.rst) 파일을 담고 있음 (사람이 읽기 위한 언어 사양)
cpython/Doc/reference
├── compound_stmts.rst # 복합문 (if, while, for, 함수 정의 등)
├── introduction.rst # 레퍼런스 문서 개요
├── index.rst # 언어 레퍼런스 목차
├── datamodel.rst # 객체, 값, 타입
├── executionmodel.rst # 프로그램 구조
├── expressions.rst # 표현식 구성 요소
├── grammar.rst # 문법 규격(Grammar/Grammar 참조)
├── import.rst # import 시스템
├── lexical_analysis.rst # 어휘 구조 (줄, 들여쓰기, 토큰, 키워드 등)
├── simple_stmts.rst # 단순문 (assert, import, return, yield 등)
└── toplevel_components.rst # 스크립트 및 모듈 실행 방법 설명예시
- Doc→reference→compound_stmts.rst 에서 간단한 예시로 with 문의 정의를 찾을 수 있음
기계가 읽을 수 있는 사양은 Grammar→python.gram이라는 단일 파일 안에 들어 있음
4.2.2 문법 파일
파서 표현식 문법(Parsing Expression Grammar, PEG) 사양을 사용하고 아래 표기법을 사용
- *: 로 반복을 표현
- : 최소 한번의 반복 표현
- []: 선택적인 부분을 표현
- | : 대안을 표현
- (): 그룹을 표현
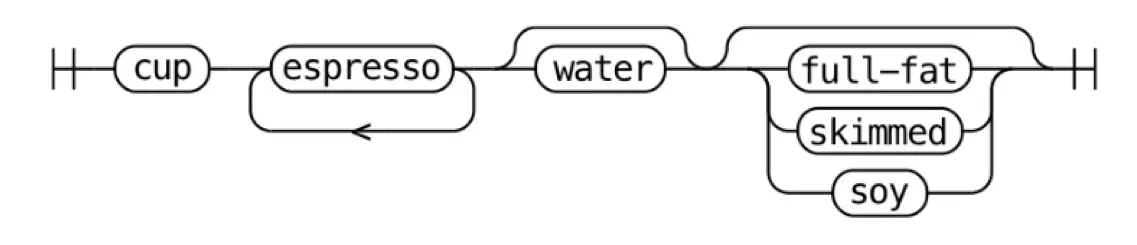
ex 1) 커피 한잔을 정의
- 컵이 있어야 함
- 최소 에스프레소 한 샷을 포함하고 여러 샷을 포함할 수 도 있음
- 우유를 사용할 수도 있지만 선택적
- 물을 사용할 수도 있지만 선택적
- 우유를 사용했다면 두유나 저지방 우유 등 여러 종류의 우유를 선택할 수 있음
coffee: 'cup' ('expresso')+ ['water'] [milk]
milk: 'full-fat' | 'skimmed' | 'soy'
철도 다이어그램 (railroad diagram)
ex 2) while 문
여러 형태로 사용할 수 있는데 가장 간단한 형태는 표현식과 : 단말 기호(terminal), 코드 블록으로 이루어짐
while finished == True:
do_things()
named_expression 대입 표현식을 사용할 수도 있음
while letters := read(document, 10):
print(letters)
while 문 다음에 else 블록을 쓸 수도 있음
while item := next(iterable):
print(item)
else:
print("Iterable is empty")
while_stmt 는 문법 파일에 다음과 같이 정의되어 있음
# Grammar/python.gram L165
while_stmt[stmt_ty]:
| 'while' a=named_expression ':' b=block c=[else_block] { _Py_While(a, b, c, EXTRA) }
- 따옴표로 둘러싸인 부분은 단말기호라는 문자열 리터럴
- 키워드는 단말 기호로 인식
- block: 한개 이상의 문장이 있는 코드 블록
- named_expression: 간단한 표현식 또는 대입 표현식을 나타냄

ex 3) try 문 (좀 더 복잡한 예시)
# Grammar/python.gram L189
try_stmt[stmt_ty]:
| 'try' ':' b=block f=finally_block { _Py_Try(b, NULL, NULL, f, EXTRA) }
| 'try' ':' b=block ex=except_block+ el=[else_block] f=[finally_block] { _Py_Try(b, ex, el, f, EXTRA) }
except_block[excepthandler_ty]:
| 'except' e=expression t=['as' z=NAME { z }] ':' b=block {
_Py_ExceptHandler(e, (t) ? ((expr_ty) t)->v.Name.id : NULL, b, EXTRA) }
| 'except' ':' b=block { _Py_ExceptHandler(NULL, NULL, b, EXTRA) }
finally_block[asdl_seq*]: 'finally' ':' a=block { a }
try 문을 사용하는 방법은 2가지
- finally 문만 붙어있는 try
- 한개 이상의 except 뒤에 else나 finally가 붙는 try

4.3 파서 생성기
- 파이썬 컴파일러는 문법 파일을 직접 사용하지 않고 파서 생성기가 문법 파일에서 생성한 파서를 사용
- 문법 파일을 수정하면 파서를 재생성한 후 CPython을 다시 컴파일해야 함
- 파서란?
- 파이썬 3.9부터 CPython은 파서 테이블 생성기(pgen 모듈) 대신 문맥 의존 문법 파서를 사용
- 기존 파서는 파이썬 3.9까지는 -X oldparser 플래그를 활성화해 사용할 수 있으며 파이썬 3.10에서 완전히 제거됨
4.4 문법 다시 생성하기
- 새로운 PEG 생성기인 pegen을 테스트해보기 위해 문법 일부를 변경해봄
# Grammar/python.gram L66 을 아래처럼 변경 (|'proceed' 추가)
| ('pass'|'proceed') { _Py_Pass(EXTRA) }변경 후 아래 명령어로 문법 파일을 다시 빌드
$ make regen-pegen
PYTHONPATH=./Tools/peg_generator python3.9 -m pegen -q c \\
./Grammar/python.gram \\
./Grammar/Tokens \\
-o ./Parser/pegen/parse.new.c
python3.9 ./Tools/scripts/update_file.py ./Parser/pegen/parse.c ./Parser/pegen/parse.new.cmakefile이 있는 폴더에서 아래 명령어를 실행하면 proceed 키워드를 사용할 수 있음을 확인
$ ./python.exe
Python 3.9.20+ (heads/3.9-dirty:011fb84db5f, Nov 8 2024, 21:32:35)
[Clang 15.0.0 (clang-1500.3.9.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> def example():
... proceed
...
>>>
>>> example()- 위 과정을 통해 CPython 문법을 수정하고 컴파일해서 새로운 CPython을 만든 시도를 한 것
4.4.1 토큰
- Grammar 폴더 내에 Tokens 파일에서 파스 트리의 leaf node에서 사용되는 고유한 토큰들을 정의함
- 각 토큰은 이름과 자동으로 생성된 고유 아이디(ID)를 가지고, 이름을 사용하면 토크타이저에서 토큰을 더 쉽게 참조할 수 있음
LPAR '('
RPAR ')'
SEMI ':'
- Tokens 파일을 수정하면 pegen을 다시 실행해야 하고 tokenize 모듈을 이용하면 토큰이 사용되는 걸 호가인할 수 있음
# test_tokens.py
def my_function():
proceed
./python.exe -m tokenize -e test_tokens.py
0,0-0,0: ENCODING 'utf-8'
1,0-1,3: NAME 'def'
1,4-1,15: NAME 'my_function'
1,15-1,16: LPAR '('
1,16-1,17: RPAR ')'
1,17-1,18: COLON ':'
1,18-1,19: NEWLINE '\\n'
2,0-2,4: INDENT ' '
2,4-2,11: NAME 'proceed'
2,11-2,12: NEWLINE '\\n'
3,0-3,1: NL '\\n'
4,0-4,0: DEDENT ''
4,0-4,0: ENDMARKER ''- 출력에서 첫번째 열은 파일에서 토큰의 위치를 의미
- def 의 경우 1,0-1,3 이라고 적혀 있는데 첫번째 줄 0번째 위치 부터 첫번재 줄 3번째 위치까지 있다는 의미
- 두번째 열: 토큰의 이름
- 세번째 열: 토큰의 값
- 출력에서 tokenize 모듈은 일부 토큰을 자동으로 추가
- utf-8 인코딩을 뜻하는 ENCODING 토큰
- 함수 정의를 마치는 DEDENT 토큰
- 파일 끝을 뜻하는 ENDMARKER 토큰
- 끝 공백
- Lib 폴더의 tokenize.py의 tokenize 모듈은 완전히 파이썬으로만 작성됨
- 디버그 빌드를 -d 플래그로 실행해 C 파서가 실행되는 과정을 자세히 보면 아래와 같음
$ ./python.exe -d test_tokens.py > file[0-0]: statements? $
> statements[0-0]: statement+
> _loop1_11[0-0]: statement
> statement[0-0]: compound_stmt
....
> small_stmt[33-33]: ('pass' | 'proceed')
> _tmp_15[33-33]: 'pass'
- _tmp_15[33-33]: 'pass' failed!
> _tmp_15[33-33]: 'proceed'
- _tmp_15[33-33]: 'proceed' failed!
....
+ statements[0-10]: statement+ succeeded!
+ file[0-11]: statements? $ succeeded!
- 내용이 길기 때문에 아래 명령어로 디버그 출력 내용을 파일로 저장해서 보면 위와같이 proceed는 키워드로 강조 표시 되어 있음
./python.exe -d test_tokens.py 2> output.txt
Grammar 폴더의 python.gram 파일을 원래대로 수정 후 아래 명령어로 문법을 다시 생성한 다음 빌드를 정리하고 다시 컴파일
$ make regen-pegen
$ make -j2 -s
반응형
'Python' 카테고리의 다른 글
| [책리뷰] 파이썬 클린 코드 Chapter 3. 좋은 코드의 일반적인 특징 (0) | 2024.11.10 |
|---|---|
| [책리뷰] CPython 파헤치기 5장. 구성과 입력 (0) | 2024.11.10 |
| pathlib 모듈 (0) | 2024.10.20 |
| [책리뷰] 파이썬 클린 코드 Chapter 2. Pythonic 코드 (2) (0) | 2024.09.29 |
| [책리뷰] 파이썬 클린 코드 Chapter 2. Pythonic 코드 (1) (0) | 2024.09.29 |