반응형
이 글은 책 컴퓨터 밑바닥의 비밀 chapter 6.5의 내용을 읽고 요약한 글입니다.
6.5 mmap: 메모리 읽기와 쓰기 방식으로 파일 처리
코드에서 메모리를 읽기 쓰는 것은 아래와 같이 배열을 정의하고 값을 할당하기만 하면 됨
int a[100];
a[10] = 2;
하지만 파일을 읽는 경우는 상대적으로 더 복잡
char buf[1024];
int fd = open("/filepath/abc.txt");
read(fd, buf, 1024);
// buf 등을 이용한 작업
- 운영체제에 파일에 접근할 수 있는 파일 서술자를 요청 후 파일의 정보를 읽을 수 있음
파일을 사용하는 것이 메모리를 사용하는 것보다 복잡한 이유
- 디스크에서 특정 주소를 지정(addressing)하는 방법과 메모리에서 특정 주소를 지정하는 방법이 다름
- CPU와 외부 장치 간 속도에 차이가 있음
파일에 대해 메모리처럼 직접 디스크의 파일을 읽고 쓸 수는 없을까?
6.5.1 파일과 가상 메모리
- 사용자 상태에서 메모리는 하나의 연속된 공간이고, 디스크에 저장된 파일도 하나의 연속된 공간
- 두 공간을 연관 짓는 방법은? → 가상 메모리
- 가상 메모리의 목적은 모든 프로세스가 각자 독점적으로 메모리를 소유하고 있다고 생각하게 하는 것
- 프로세스가 만나는 주소 공간은 가상이기 때문에 ‘수작을 부려’작업할 수 있는 공간이기도 함
- 파일은 개념적으로 연속된 디스크 공간에 저장되어 있다고 생각할 수 있으므로 이 공간을 프로세스 주소 공간에 직접 mapping할 수 있음
- 길이가 200바이트인 파일을 프로세스 주소 공간에 매핑한 결과로 파일이 600~799 주소 범위에 위치하고 있다고 가정하면, 이 주소 공간에서 바이트 단위로 파일을 처리할 수 있음
6.5.2 마술사 운영 체제
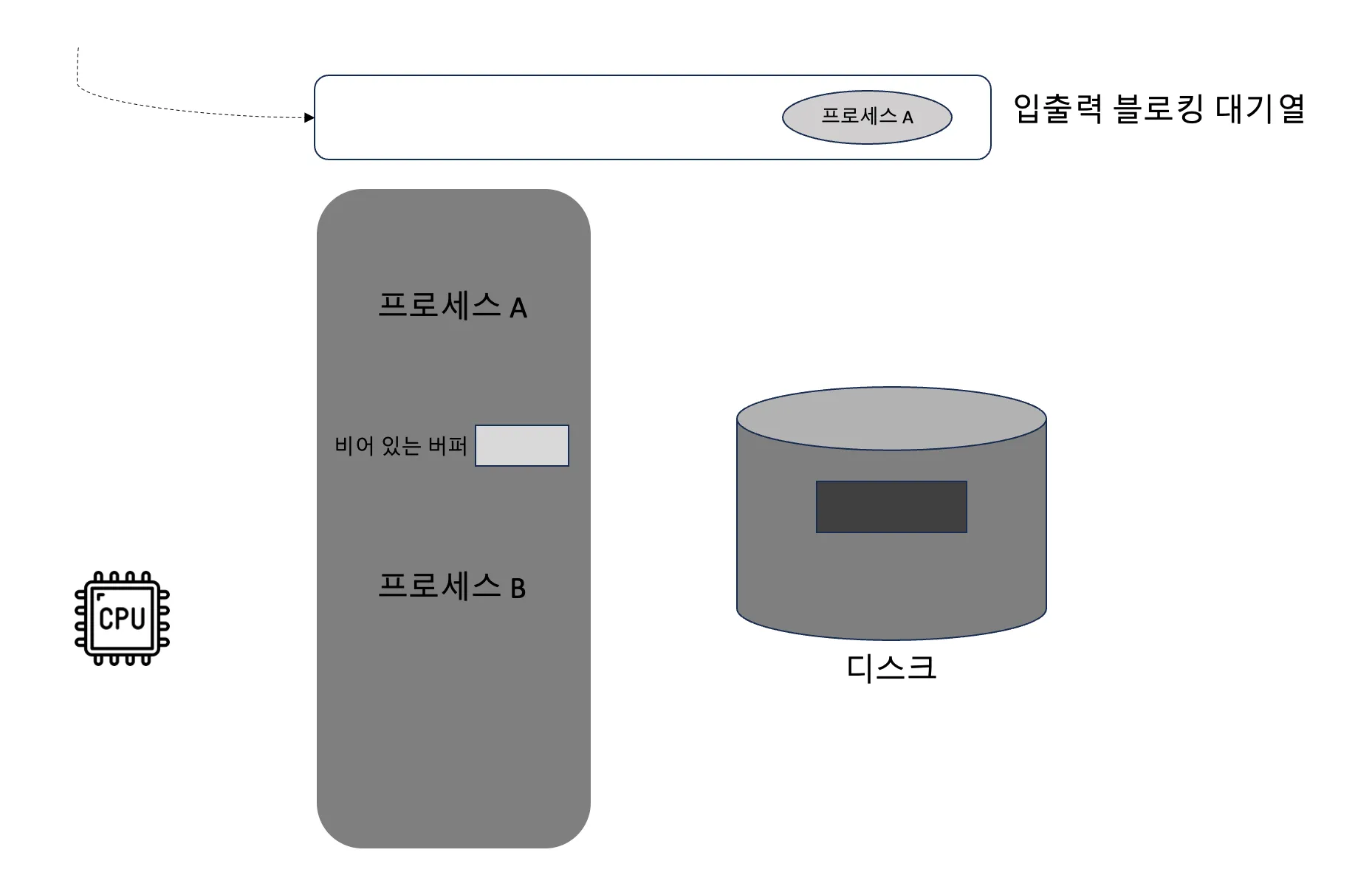
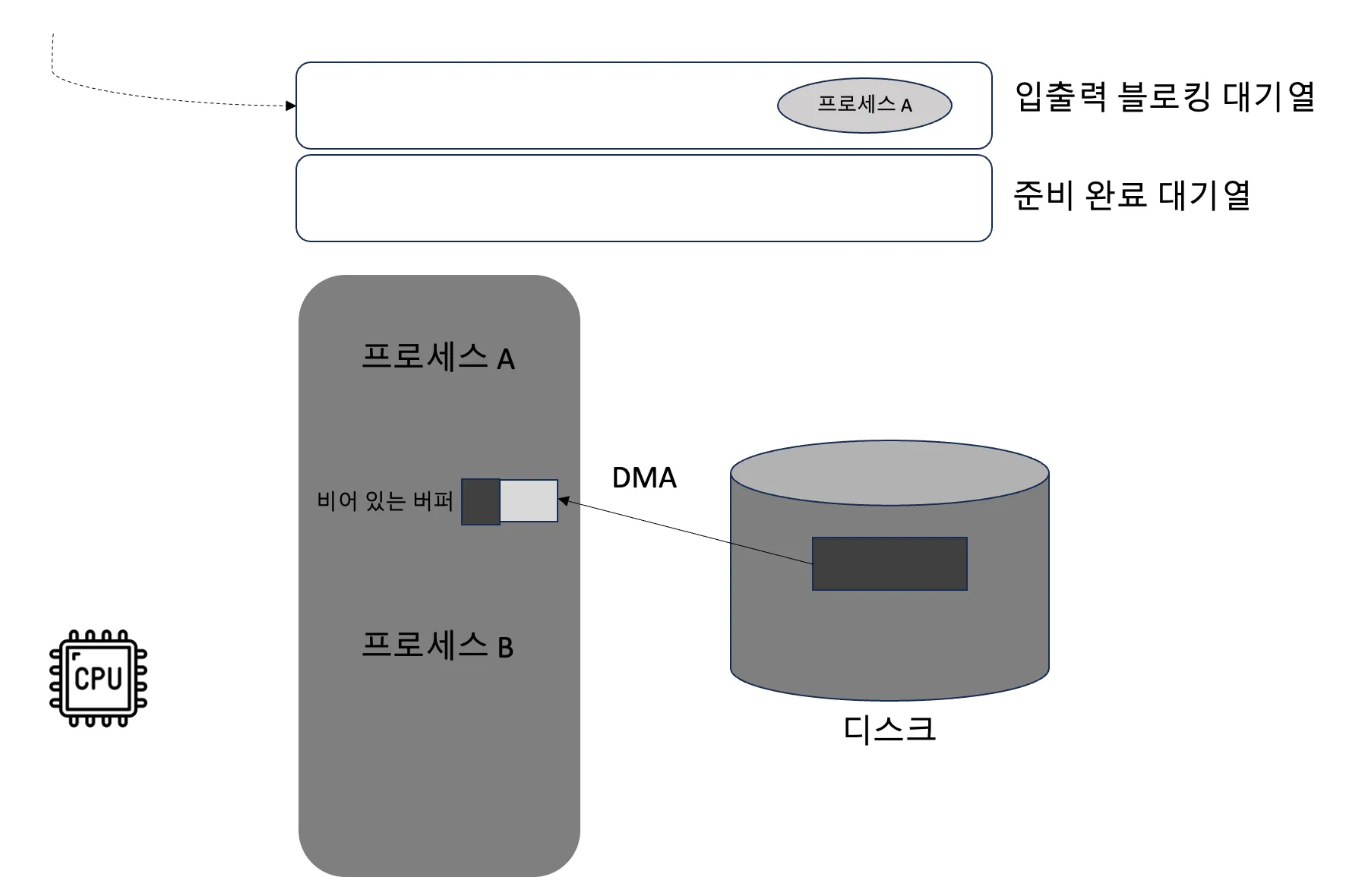
- 600~799 범위의 주소 공간을 읽을 때, 대응하는 파일이 아직 메모리에 적재되지 않아 페이지 누락(page fault) 인터럽트가 발생할 수 있음
- 이후 CPU가 운영 체제의 인터럽트 처리함수를 실행하며, 실제 디스크 입출력 요청이 시작
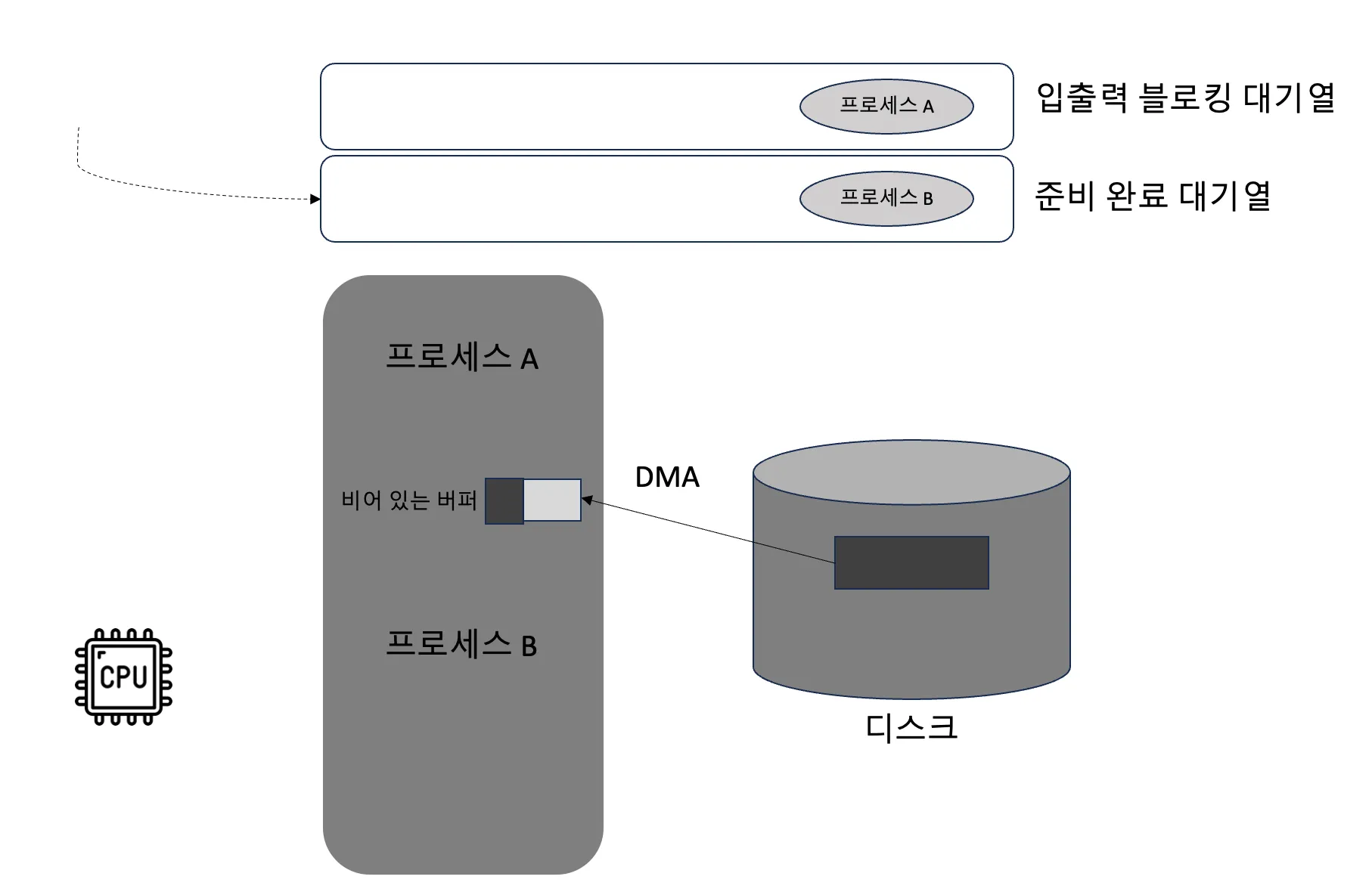
- 파일을 메모리로 읽고 가상 메모리와 실제 메모리의 연결이 수립되면 프로그램에서 메모리를 읽고 쓰듯이 직접 디스크의 내용을 사용할 수 있음
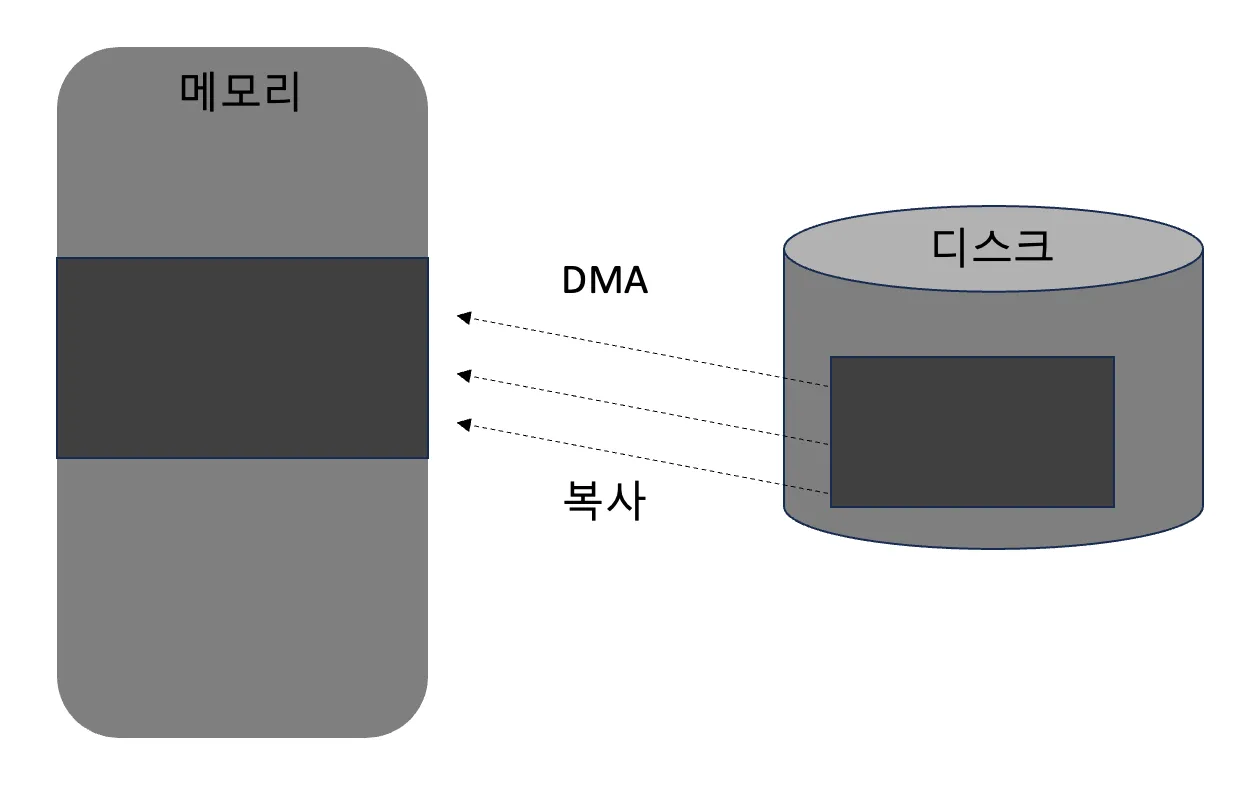
- mmap을 사용하더라도 실제로 디스크를 읽고 써야 하기는 하지만 이 과정은 운영체제가 진행함
- 또한 가상 메모리를 경유하기 때문에 고수준 계층에 있는 사용자는 신경쓸 필요 없음
6.5.3 mmap 대 전통적인 read/write 함수
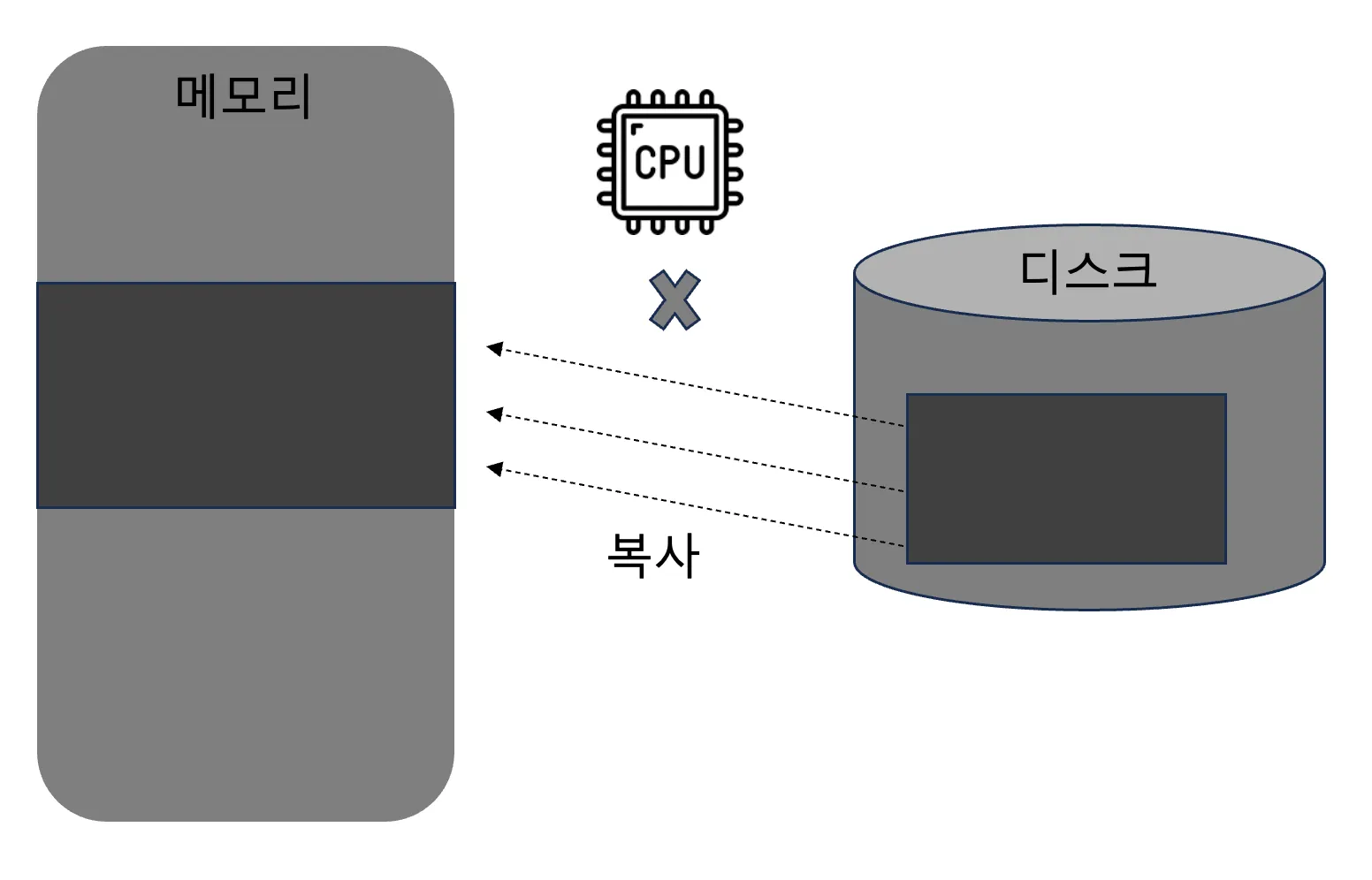
- read/write 함수 같은 입출력 함수는 저수준 계층에 시스템 호출을 사용함 → 파일을 읽고 쓸 때 데이터를 커널 상태 ↔ 사용자 상태로 복사해야 해서 큰 부담을 수반
- mmap은 디스크의 파일을 읽고 쓸 때는 시스템 호출과 데이터 복사가 주는 부담이 없음. 하지만 커널은 프로세스 주소 공간관 파일의 mapping 관계를 유지하기 위해 특정 데이터 구조를 사용해야 하며 이 역시 성능에 부담을 가져옴
- 이외에 page fault 문제가 있어 인터럽트가 발생하면 이에 상응하는 인터럽트 처리 함수가 실제로 파일을 메모리에 적재해야 함
⇒ mmap 과 read/write 함수의 성능 비교를 할 때 실제 구체적인 상황에서 각각의 방식에 대한 부담을 비교하여 선택해야 함
6.5.4 큰 파일 처리
- 큰 파일이란 물리 메모리 용량을 초과할 정도의 크기를 가진 파일을 의미
- 전통적인 read/write 함수를 사용하면 파일을 조금씩 나누어 메모리에 적재해야 하며, 파일의 일부분에 대한 처리가 끝나면 다시 다음 부분에 대한 처리를 하는 방식으로 너무 많은 메모리를 요청하면 OOM 문제가 발생할 수 있음
- mmap을 사용하면 가상 메모리의 도움하에 프로세스 주소 공간이 충분하다면 큰 파일 전체를 프로세스 주소 공간에 직접 mapping할 수 있으며 해당 파일의 크기가 실제 물리 메모리의 크기보다 크더라도 아무 문제 없음
- mmap을 호출할 때 매개변수가 MAP_SHARED 라면 사상된 영역의 변경 내용은 디스크의 파일에 직접 기록됨. 시스템은 작업중인 파일의 크기가 물리 메모리의 크기보다 큰지 전혀 관심 없음
- 매개변수가 MAP_PRIVATE 인 경우, 시스템이 실제로 메모리를 할당한다는 의미로 물리 메모리의 크기에 교환 영역(swap area)의 크기를 더한 크기가 기준이 됨
6.5.5 동적 링크 라이브러리와 공유 메모리
- 동적 링크 라이브러리의 경우 이를 차조하는 프로그램이 아무리 많더라도 실행 파일에는 라이브러리의 코드와 데이터가 포함되지 않음
- 라이브러리를 참조하는 모든 프로그램이 메모리에 적자되더라도 동일한 동적 라이브러리를 공유하므로 디스크와 메모리의 공간을 절약할 수 있음
mmap으로 해당 라이브러리를 사용하는 모든 프로세스의 주소 공간에 직접 mapping할 수 있는데 여러 프로세스는 모두 해당 라이브러리가 자신의 주소 공간에 적재되었다고 생각하지만, 실제 물리 메모리에서 이 라이브러리가 차지하는 공간은 한개 크기일 뿐임.
반응형
'OS' 카테고리의 다른 글
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.4 높은 동시성의 비결: 입출력 다중화 (0) | 2024.10.13 |
|---|---|
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.3 파일을 읽을 때 프로그램에는 어떤 일이 발생할까? (0) | 2024.10.06 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.2 디스크가 입출력을 처리할 때 CPU가 하는 일은 무엇일까? (0) | 2024.10.06 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.1 CPU는 어떻게 입출력 작업을 처리할까? (2) (0) | 2024.10.06 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.1 CPU는 어떻게 입출력 작업을 처리할까? (1) (0) | 2024.09.29 |