이 글은책컴퓨터 밑바닥의 비밀chapter 3.2-3.3 의 내용을 읽고 요약한 글입니다.
3.2 프로세스는 메모리 안에서 어떤 모습을 하고 있을까?
3.2.1 가상 메모리: 눈에 보이는 것이 항상 실제와 같지는 않다
모든 프로세스의 코드 영역은 0x400000에서 시작
서로 다른 두개의 프로세스가 메모리를 할당하기 위해 malloc을 호출하면 동일한 시작 주소를 반환할 가능성이 매우 높음
Ubuntu 에서 테스트
// malloc_test.c
#include <stdio.h>
#include <stdlib.h>
int main() {
void *ptr = malloc(10); // Allocate 10 bytes
printf("Address returned by malloc: %p\\n", ptr);
free(ptr); // Don't forget to free the memory
return 0;
}
$ ./malloc_test Address returned by malloc: 0x56342fa8d260 $ ./malloc_test Address returned by malloc: 0x55a3e5a9d010
다른 주소가 반환됨. 이유는? → ASLR 이라는 기술이 최근 OS에는 적용되어있음
ASLR (Address Space Layout Randomization)
스택, 힙, 동적 라이브러리 영역의 주소를 랜덤으로 배치해서 공격에 필요한 target address를 예측하기 어렵게 만드는 기술
ASLR 기술을 끄고 테스트하면 같은 주소가 반환되는 걸 볼 수 있다
$ echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
$ ./malloc_test
$ Address returned by malloc: 0x40068c
$ ./malloc_test
$ Address returned by malloc: 0x40068c
두 프로세스가 모두 같은 주소에 데이터를 쓸 수 있다는 의미인데 괜찮은가?
⇒ 주소값은 가짜 주소(가상 메모리 주소)이고 메모리에 조작이 일어나기 전 실제 물리 메모리 주소로 변경되기 때문에 문제 되지 않음
실제 물리 메모리 구조 예시
주목할 2가지 사항
프로세스는 동일한 크기의 chunk로 나뉘어 물리 메모리에 저장 - 위 그림에서 힙 영역은 3개의 chunk로 나뉨
모든 조각은 물리 메모리 전체에 무작위로 흩어져 있음
보기에 아름답지 않지만 운영 체제가 프로세스에 균일한 가상의 주소 공간을 제공하는 것을 방해하지는 않음 → 가상 메모리와 물리 메모리 사이의 mapping을 나타내는 page table로 관리
3.2.2 페이지와 페이지 테이블: 가상에서 현실로
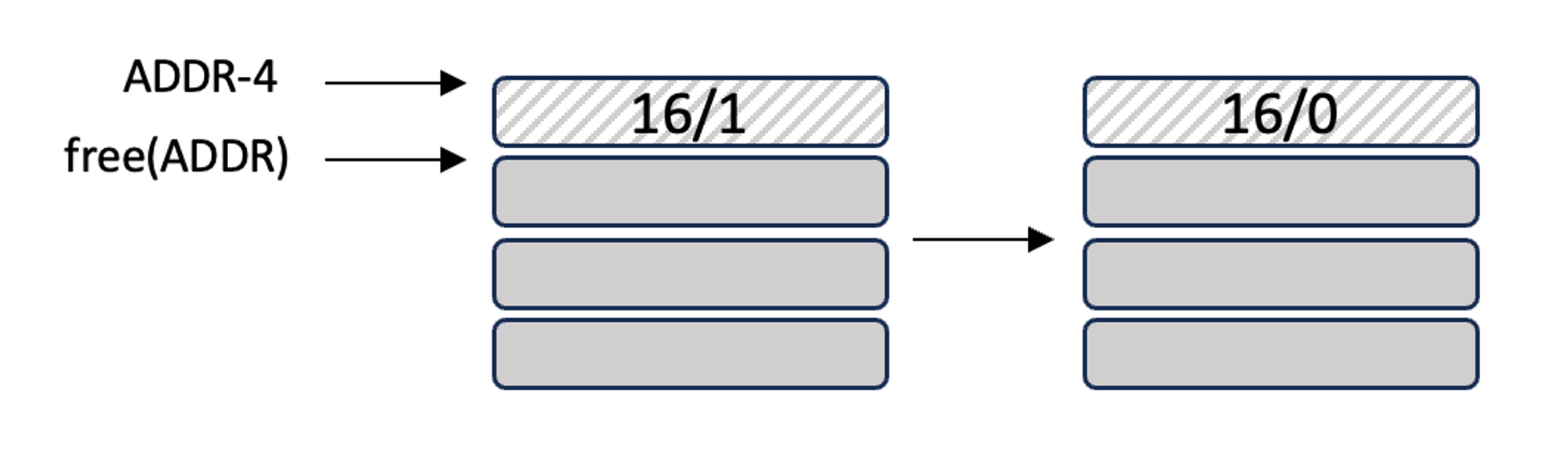
각각의 프로세스에는 단 하나의 페이지 테이블만 있어야 함
mapping은 ‘page’ 라는 단위로 이루어짐
프로세스의 주소 공간을 동일한 크기의 ‘조각’으로 나누고, 이 ‘조각’을 페이지(page)라고 부름
그러므로 두 프로세스가 동일한 메모리 주소에 기록하더라도 페이지 테이블 통해 실제는 다른 물리 메모리 주소에 저장됨
3.3 스택 영역: 함수 호출은 어떻게 구현될까?
아래 코드의 문제점은?
void func(int a)
{
if(a>100000000)
{
return;
}
int arr[100] = { 0 };
func(a + 1);
}
함수 실행 시간 스택(runtime stack)과 함수 호출 스택(call stack) 이해 필요
3.3.2 함수 호출 활동 추적하기: 스택
A, B, C, D 4가지 단계가 존재하고 아래그림 처럼 의존성을 가짐
단계별로 진행 과정
A→B→D→B→A→C→A
선입 선출(Last In First Out, LIFO) 순서로 stack 과 같은 데이터 구초가 처리하기 적합
3.3.3 스택 프레임 및 스택 영역: 거시적 관점
함수 실행시의 자신만의 ‘작은 상자’가 필요한데 이를 call stack 혹은 stack frame 이라고 함
스택은 낮은 주소 방향으로 커지므로 아래와 같이 표현됨
stack frame에는 어떤 정보들이 포함되는지?
3.3.4 함수 점프와 반환은 어떻게 구현될까?
함수 A가 함수 B를 호출하면, 제어권이 A에서 B로 옮겨짐
제어권: CPU가 어떤 함수에 속하는 기계 명령어를 실행하는지 의미
제어권이 넘어갈 때는 2가지 정보가 필요함
반환(return): 어디에서 왔는지에 대한 정보
함수 A의 명령어가 어디까지 실행되었는지에 대한 정보
점프(jump): 어디로 가는지에 대한 정보
함수 B의 첫 번째 기계 명령어가 위치한 주소
위의 정보는 어디서 가져오는지? → 스택 프레임!
함수 A가 함수 B를 호출할 때 CPU는 함수 A의 기계 명령어(주소: 0x400564)를 실행중이라 가정
CPU는 다음 기계 명령어를 실행하는데 call 뒤에 명령어 주소가 함수 B의 첫번째 기계 명령어
이 명령어를 실행한 직후 CPU는 함수 B로 점프하게 됨
함수 B실행이 완료되면 어떻게 함수 A로 돌아오나?
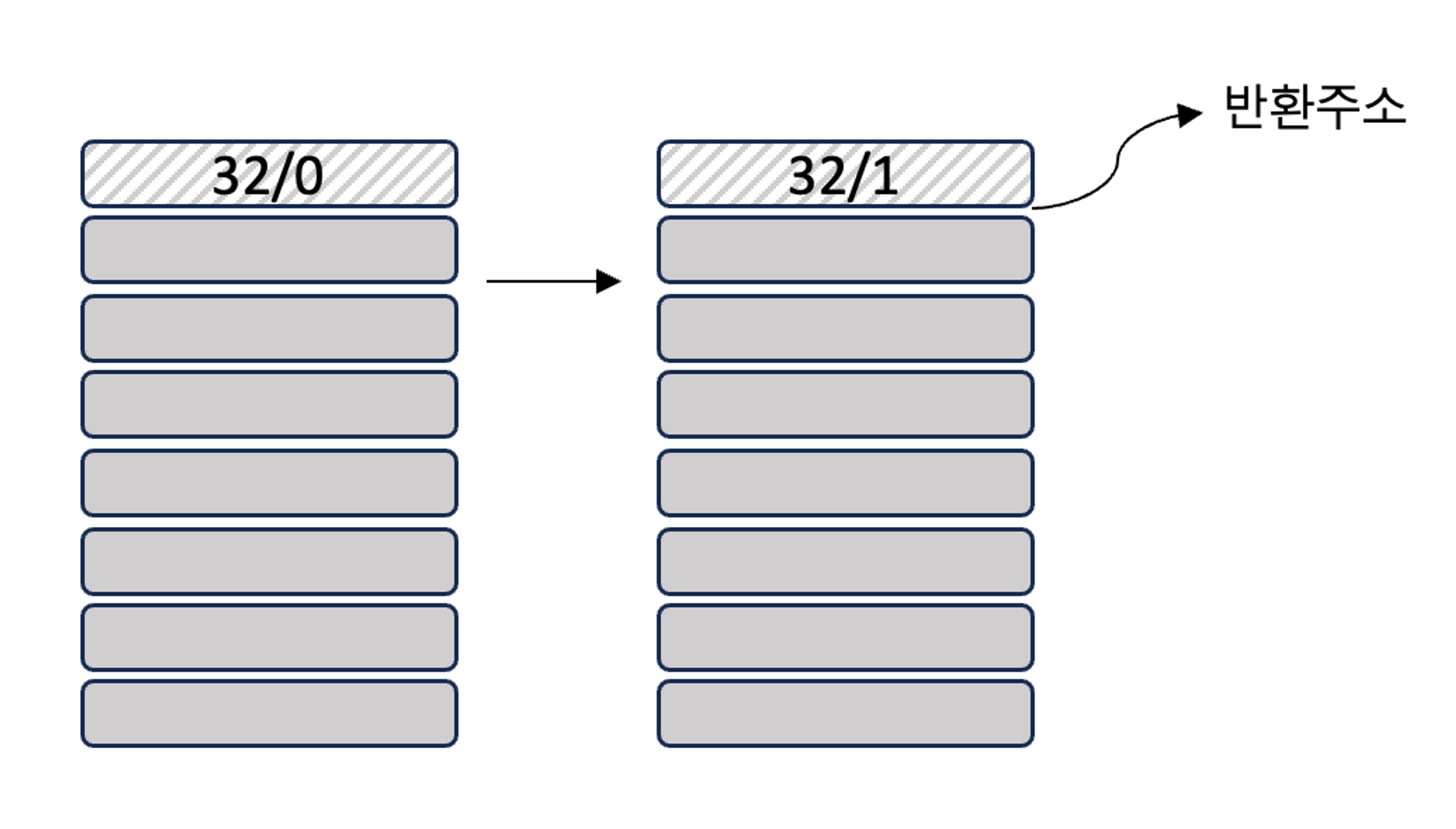
call 명령어 실행 후 지정한 함수로 점프 + call 명령어 다음 위치 주소(0x40056a)를 함수 A의 스택 프레임에 넣음
call 명령어를 실행하면 반환주소가 스택 프레임에 저장됨
반환 주소가 추가되면서 스택 프레임이 아래 방향으로 조금 커짐
함수 B에 대응하는 기계 명령어를 실행하면서 B에 대한 스택 프레임도 추가됨
함수 B의 마지막 기계 명령어인 ret은 CPU에 함수 A의 스택 프레임에 저장된 반환주소로 점프하도록 전달하는 역할
3.3.5 매개변수 전달과 반환값은 어떻게 구현될까?
대부분의 경우 레지스터를 통해 매개변수와 반환값을 전달
함수 A가 B를 호출하면, A는 매개변수를 상응하는 레지스터에 저장
CPU가 함수 B를 실행할 때 이 레지스터에서 매개변수 정보를 얻을 수 있음
CPU 내부의 레지스터 수가 제한되는 경우 나머지는 스택 프레임에 넣음
스택 프레임에 함수 호출에 필요한 매개변수 보관
3.3.6 지역 변수는 어디에 있을까?
레지스터에 저장할 수 있지만 로컬 변수가 레지스터 수보다 많으면 스택프레임에 저장
3.3.7 레지스터의 저장과 복원
함수 A와 B가 지역변수 저장을 위해 모두 레지스터를 사용하면 값이 덮어써 질 수 있음
그렇기 때문에 초기에 저장된 값을 레지스터에서 사용하고 나면 다시 그 초기값을 함수의 스택 프레임에 저장해야 함
3.3.8 큰 그림을 그려보자, 우리는 지금 어디에 있을까?
void func(int a)
{
if(a>100000000)
{
return;
}
int arr[100] = { 0 };
func(a + 1);
}
앞에서 본 코드를 다시 보면, 자기 자신 함수를 100000000번 호출
호출 할 때마다 스택 프레임이 함수 실행시 정보를 저장하기 위해 생성되며, 함수 호출 단계가 증가하며 스택 영역이 점점 더 많은 메모리 차지 → stack overflow 발생
첫번째 줄 코드에서 사용자가 데이터를 보내지 않는한 recv(fd1, buf1) 는 반환되지 않으므로 서버가 두 번째 사용자의 데이터를 수신하고 처리할 기회가 사라짐
더 좋은 방법은?
운영체제에게 내용을 전달하는 작동 방식 사용
‘저 대신 소켓 서술자 열 개를 감시하고 있다가, 데이터가 들어오면 저에게 알려주세요’
입출력 다중화라고 하며 리눅스 세계에서 가장 유명한 것이 epoll
// epoll 생성
epoll_fd = epoll_create();
// 서술자를 epoll이 처리하도록 지정
Epoll_ctl(epoll_fd, fd1, fd2, fd3, fd4, ...);
while(1)
{
int n = epoll_wait(epoll_fd); // getEvent 역할로 지속적으로 다양한 이벤트 제공
for(i=0;i<n;i++)
{
// 특정 이벤트 처리
}
}
epoll은 이벤트 순환(event loop)을 위해 탄생했음
위 사진처럼 epoll을 통해 이벤트 소스 문제가 해결됨
두번쨰 문제: 이벤트 순환과 다중 스레드
이벤트 핸들러에 2가지 특징이 있다고 가정
입출력 작업이 전혀 없음
처리함수가 간단해서 소요시간이 매우 짧음
이 경우 간단히 모든 요청을 단일스레드에서 순차적으로 처리가능
하지만 CPU시간을 많이 소모하는 사용자 요청을 처리해야 한다면?
요청의 처리 속도를 높이고 다중 코어를 최대한 사용하려면 다중 스레드의 도움이 필요
이벤트 핸들러는 더 이상 이벤트 순환과 동일한 스레드에서 실행되지 않고 독립적인 스레드에 배치됨
이벤트 순환은 요청을 수신하면 간단한 처리 후 바로 각각의 작업자 스레드에 분배
작업자 스레드를 thread pool로 구현하는 것도 가능
⇒ 이러한 설계 방법을 reactor pattern(반응자 패턴)이라고 부름
카페/음식점에서 주문 받는 사람(이벤트 순환)과 요리하는 사람(작업자 스레드)을 다르게 운영하는 것과 같다.
이벤트 순환과 입출력
요청 처리 과정에 입출력 작업도 포함된다고 가정하면 2가지 상황 발생 가능
입출력 작업에 대응하는 논 블로킹 인터페이스가 있는 경우
직접 논블로킹 인터페이스를 호출해도 스레드가 일시 중지 않고, 인터페이스가 즉시 반환되므로 event loop에서 직접 호출하는 것이 가능
입출력 작업에 블로킹 인터페이스만 있는 경우
이때는 절대로 event loop에서 어떤 블로킹 인터페이스도 호출하면 안됨
호출하게 된다면 순환 스레드가 일지 중지될 수 있음
블로킹 입출력 호출이 포함된 작업은 작업자 스레드에 전달해야 함
비동기와 콜백 함수
비지니스가 발전하면서 서버 기능은 점점 복잡해지고 여러 서버가 조합되어 하나의 사용자 요청을 처리
void handler(request)
{
A;
B;
GetUserInfo(request, response); // A 서버에 요청 후 응답을 받아 매게변수 response에 저장
C;
D;
GetQueryInfo(request, response); // B 서버에 요청 후 응답을 받아 매게변수 response에 저장
E;
F;
GetStorkInfo(request, response); // C 서버에 요청
G;
H;
}
Get 으로 시작하는 호출은 모두 블로킹 호출로 CPU 리소스를 최대한 활용하지 못할 가능성이 매우 높음 → 비동기 호출로 수정 필요
함수 A가 B를 호출할 때, 함수 B를 호출함과 동시에 OS가 함수 A가 실행중인 스레드나 프로세스를 일시 중지 시킨다 → 블로킹
그렇지 않으면 → 논-블로킹
블로킹 호출 핵심은 스레드/프로세스가 일시 중지되는 것
모든 함수 호출이 호출자의 스레드를 일시 중지 시키는 것은 아님
int sum(int a, int b)
{
return a + b;
}
void func()
{
int r = sum(1, 1);
}
위 코드는 운영체제가 func 함수 호출 시 해당 스레드를 중지시키지 않음. 핵심은 입출력
블로킹의 핵심 문제: 입출력
입출력 요청 완료시간은 CPU의 클럭 주파수보다 훨씬 느림
입출력 과정이 실행되는 동안 CPU 제어권을 다른 스레드로 넘겨 다른 작업을 할 수 있도록 해야 함
이후 입출력 작업이 완료되면 다시 CPU제어권을 우리 쓰레드/프로세스로 받아와 다음 작업을 실행할 수 있도록 함
CPU 제어권을 상실했다가 되찾는 시간 동안 블로킹되어 일시 중지됨
스레드 A가 입출력 작업을 실행하여 블로킹되면 CPU는 스레드 B에 할당됨
스레드 B가 실행되는 동안 OS는 입출력 작업이 완료된 것을 확인하면 다시 스레드 A에 CPU 할당
논블로킹과 비동기 입출력
네트워크 데이터 수신을 예로 설명. 데이터를 수신하는 함수인 recv가 논블로킹이면 이 함수를 호출할 때 OS는 스레드를 일시 중지시키는 대신 recv 함수를 즉시 반환
호출 스레드는 자신의 작업을 계속 진행하고 데이터 수신 작업은 커널이 처리
데이터를 언제 수신했는지 알 수 있는 방법은?
논블로킹 방식의 recv 함수 외에 결과를 확인하는 함수를 함께 제공하고, 해당 함수를 호출하여 수신된 데이터가 있는지 확인
데이터가 수신되면 스레드에 메시지나 신호등을 전송하는 알림 작동 방식
recv 함수를 호출 할 때 데이터 수신 처리를 담당하는 함수를 콜백 함수에 담아 매개변수로 전달할 수 있음(recv 함수가 콜백 함수를 지원해야 함)
논블로킹 호출이며, 이런 유형의 입출력 작업을 비동기 입출력 이라고도 함
피자 주문에 비유하기
피자를 직접 주문하러 피자가게에 가서 주문하고 기다려 받는것: 블로킹
피자 전화로 주문 후 받는 것: 논 블로킹
피자 완성됬는지 계속 체크하면? 동기
일반적으로는 비동기
동기와 블로킹
블로킹 호출은 확실한 동기 호출
동기호출은? 블로킹 호출이 아닐 수 있음
sum 함수에 대한 호출은 동기이지만 funcA가 sum 함수 호출을 했다고 해서 블로킹되거나 하지 않음
int sum(int a, int b)
{
return a + b;
}
void func()
{
int r = sum(1, 1);
}
비동기와 논블로킹
네트워크 데이터 수신을 예로 들어 설명
데이터를 수신하는 recv 함수를 논블로킹 호출로 설정하기 위해 flag 값 추가(NON_BLOCKING_FLAG)
void handler(void *buf)
{
//수신된 네트워크 데이터를 처리
}
while(true)
{
fd = accept();
recv(fd, buf, NON_BLOCKING_FLAG, handler); // 호출 후 바로 반환, 논블로킹
}
recv 함수는 논블로킹 호출 → 네트워크 데이터를 처리해주는 handler 함수를 콜백 함수로 전달, 즉 비동기이자 논 블로킹
하지만 데이터 도착을 감지하는 전용 함수인 check 함수를 제공해서 아래와 같이 구성한다면,
void handler(void *buf)
{
//수신된 네트워크 데이터를 처리
}
while(true)
{
fd = accept();
recv(fd, buf, NON_BLOCKING_FLAG, handler); // 호출 후 바로 반환, 논블로킹
while (!check(fd))
{
// 순환 감지
;
}
handler(buf);
}
while 문에서 끊임없이 데이터를 도착하기 전까지 체크하기 때문에 그 전에 handler 함수를 사용할 수 없음 ⇒ recv 함수는 논블로킹이지만 전체적인 관점에서 이 코드는 동기
상사가 프로그래머에게 일을 시킬 때, 옆에서 계속 기다리고 있으면 동기, 일을 시키고 다른 일을 하면 비동기라고 예를 들어 설명
또 다른 예로 전화통화와 이메일을 비교해보면,
전화통화 : 상대방이 말할 때 들으며 기다려야 함(동기)
이메일: 작성하는 동안 다른 사람들은 다른 일 처리 가능(비동기)
동기 호출
일반적인 함수 호출
funcA()
{
// funcB 함수가 완료될 때까지 기다림
funcB();
// funcB 함수는 프로세스를 반환하고 계속 진행
}
funcA와 funcB 함수가 동일한 스레드에서 실행됨
입출력 작업의 경우,
...
read(file, buf); // 여기에서 실행이 중지됨
...
// 파일 읽기가 완료될 때가지 기다렸다가 계속 실행함
최하단 계층은 실제로 system call로 운영체제에 요청을 보냄
파일 읽기 작업을 위해 read 호출 스레드를 일시 중지하고, 커널이 디스크 내용을 읽어 오면 일시 중지 되었던 스레드가 다시 깨어남 (Blocking input/output 이라고 함)
Blocking input/output
비동기 호출
디스크의 파일 읽고 쓰기, 네트워크 IO, 데이터 베이스 작업처럼 시간이 많이 걸리는 입출력 작업을 백그라운드 형태로 실행
read(file, buf); // 여기에서 실행이 중지되지 않고 즉시 반환
// 이후 내용의 실행을 블로킹하지 않고 바로
read 함수가 비동기 호출되면 파일 읽기 작업이 완료되지 않은 상태에서도 read 함수는 즉시 반환될 수 있음
호출자가 블로킹 되지 않고 read 함수가 즉시 반환되기 때문에 다음 작업을 실행할 수 있음
그럼 비동기 호출에서 파일 읽기 작업이 언제 완료되었는지 어떻게 알 수 있을까? 이 경우, 처리에 대한 2가지 상황이 있을 수 있음
호출자가 실행 결과를 전혀 신경쓰지 않을 때
호출자가 실행 결과를 반드시 알아야 할 때
1. 호출자가 실행 결과를 전혀 신경쓰지 않을 때
void handler(void* buf)
{
... // 파일 내용 처리 중
}
read(buf, handler)
"계속해서 파일을 읽고, 작업이 완료되면 전달된 함수(handler)를 이용해 파일을 처리해주세요." ⇒ 파일 내용은 호출자 스레드가 아닌 콜백 함수가 실행되는 다른 스레드(호출되는 스레드) 또는 프로세스 등에서 처리
2. 호출자가 실행 결과를 반드시 알아야 할 때
notification 작동 방식을 사용하는 것
작업 실행이 완료되면 호출자에게 작업 완료를 알리는 신호나 메시지를 보내는 것
결과 처리는 이전과 마찬가지로 호출 스레드에서 함
웹 서버에서 동기와 비동기 작업
아래의 작업을 한다고 가정
A, B, C 세 단계를 거친 후 데이터 베이스를 요청
데이터 베이스 요청 처리가 완료 되면 D, E, F 세 단계를 거침
A, B, C, D, E, F 단계에는 입출력 작업이 포함되어 있지 않음
// 사용자 요청을 하는 단계
A;
B;
C;
데이터 베이스 요청;
D;
E;
F;
먼저 가장 일반적인 동기 처리 방식
// 메인 스레드
main_thread()
{
while(1)
{
요청 수신;
A;
B;
C;
데이터베이스 요청을 전송하고 결과가 반환될 때까지 대기;
D;
E;
F;
결과 반환;
}
}
// 데이터베이스 스레드
database_thread()
{
while(1)
{
요청 수신;
데이터베이스 처리;
결과 반환;
}
}
데이터 베이스 요청 후 주 스레드가 블로킹 되어 일시 중지됨
데이터 베이스 처리가 완료된 시점에서 D, E, F가 계속 실행됨
주 스레드에서 빈공간은 유휴 시간(idle time)으로 기다리는 과정
유휴 시간을 줄이기 위해서 비동기 작업을 활용할 수 있다
1. 주 스레드가 데이터 베이스 처리 결과를 전혀 신경 쓰지 않을 때
주 스레드는 데이터 베이스 처리 완료 여부 상관하지 않음
데이터베이스 스레드가 D, E, F 세 단계를 자체적으로 직접 처리
데이터 베이스 처리 후 DB 스레드가 D, E, F 세 단계를 알 수 있는 방법은?
콜백 함수
void handle_DEF_after_DB_query()
{
D;
E;
F;
}
주 쓰레드가 데이터베이스 처리 요청을 보낼 때 위 함수를 매개변수로 전달
DB_query(request, handle_DEF_after_DB_query);
데이터 베이스 쓰레드는 데이터 베이스 요청을 처리한 후 handle_DEF_after_DB_query 함수 호출하기만 하면 됨
이 함수를 데이터 베이스 쓰레드에 정의하고 직접 호출하는 대신 콜백 함수를 통해 전달받아 실행하는 이유은?
⇒ 소프트웨어 조직 구조 관점에서 볼 때 데이터베이스 쓰레드에서 해야 할 작업이 아니기 때문