이 글은 책 컴퓨터 밑바닥의 비밀 chapter 5.2의 내용을 읽고 요약한 글입니다.
5.2.1 프로그램 지역성의 원칙
프로그램 지역성의 원칙(locality of reference or principle of locality)
- 본질은 매우 규칙적으로 메모리에 접근한다는 것으로 크게 2가지 종류가 있음
(1) 시간적 지역성 (temporal locality)

- 프로그램이 메모리 조각에 접근하고 나서 이 조각을 여러번 참조하는 경우를 이야기 함
- 캐시 친화성이 매우 높은데, 데이터가 캐시에 있는한 메모리에 접근하지 않아도 반복적으로 캐시의 적중이 가능하다는 단순한 이유
(2) 공간적 지역성(spatial locality)
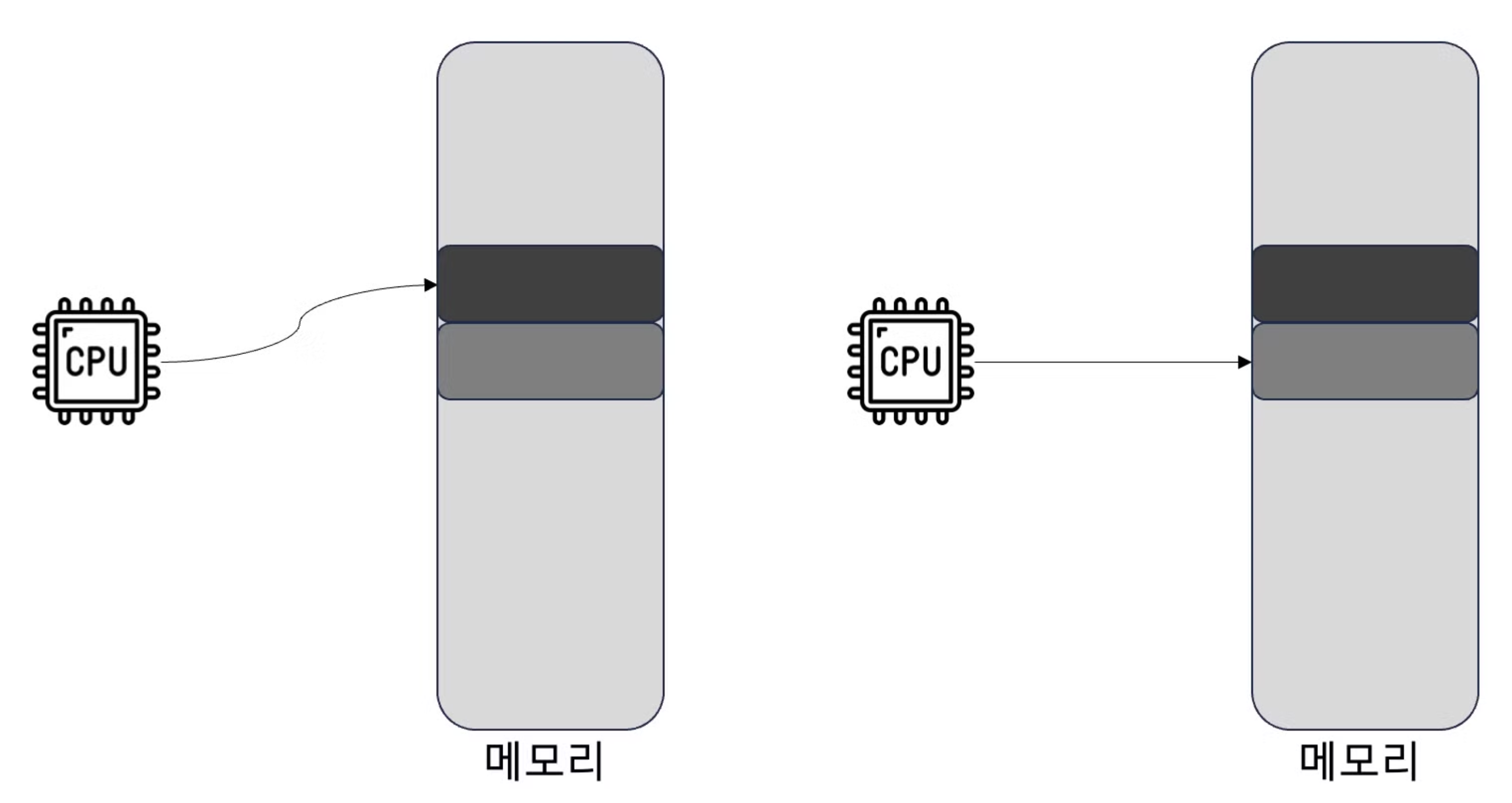
- 캐시가 적중하지 않으면 메모리의 데이터를 캐시에 적재해야 함
- 일반적으로 요청한 메모리의 인접 데이터도 함께 캐시에 저장되므로 프로그램이 인접 데이터에 접근할 때 캐시가 적중하게 됨
5.2.2 메모리 풀 사용
- 메모리를 동적으로 할당받을 때 일반적으로 malloc을 이용
- 메모리 조각 N개를 할당받을 때 malloc을 사용하면 N개 조각이 힙 영역의 이곳 저곳에 흩어져 공간적 지역성에 좋지 않음
- 메모리 풀 기술은 커다란 메모리 조각(연속적인 메모리 공간)을 미리 할당받으며 메모리 요청/해제 할 때 더 이상 malloc을 거치지 않아 캐시 친화적
5.2.3 struct 구조체 재배치
Linked list에 특정 조건을 만족하는 노드가 있는지 판단하려고 할 때, 구조체는 다음과 같이 정의
#define SIZE 100000
struct List
{
List* next;
int arr[SIZE];
int value;
}Linked list의 노드에는 필요한 값 value와 다음 노드를 가리키는 next 포인터 외에도 배열 arr이 포함되어있음
bool find(struct List* list, int target)
{
while(list)
{
if(list->value == target)
return true;
list = list->next;
}
return false;
}- 위 코드에서 빈번하게 사용되는 항목은 next 포인터와 value값이며, 배열 arr은 전혀 사용되지 않음
- 하지만 next 포인터와 value 값이 배열 arr에 의해 멀리 떨어져 있기 때문에 공간적 지역성이 나빠질 수 있어 아래 처럼 함께 배치 → 캐시 적중률 상승시킬 수 있음.
#define SIZE 100000
struct List
{
List* next;
int value; // next 아래에 value
int arr[SIZE];
}
5.2.4 핫 데이터와 콜드 데이터의 분리
- 핫데이터 (hot data): 더 빈번하게 사용되는 데이터
- 콜드 데이터(cold data): 덜 빈번하게 사용되는 데이터
위 코드에서 next, value는 핫데이터, arr는 콜드 데이터라고 할 수 있음
일반적으로 Linked list에 노드가 하나뿐인 경우는 거의 없으며, 노드가 비교적 많을 때에는 캐시해야 할 노드가 비교적 많아짐 → 캐시 용량은 제한적!
Linked list 자체가 차지하는 저장 공간이 클수록 캐시에 저장할 수 있는 노드는 줄어듬. 아래와 같이 배열 arr을 다른 구조체에 넣고 List 구조체 안에 이 구조체를 가리키는 포인터를 추가할 수 있음
#define SIZE 100000
struct List
{
List* next;
int value; // next 아래에 value
strcut Arr* arr;
};
struct Arr
{
int arr[SIZE];
};
- 콜드 데이터와 핫 데이터를 분리하면 더 나은 지역성을 얻을 수 있는데 이런 방법을 사용하려면 각 항목하다 접근 빈도를 알고 있어야 함
5.2.5 캐시 친화적인 데이터 구조
- 지역성 원칙 관점에서 배열이 linked list보다 나음
- C++, std::vector 컨테이너가 std::list 컨테이너 사용보다 나음
- 실제로 사용할 때는 캐시 친화적 여부를 포함하여 구체적인 상황에 맞추어 선택해야 함
- 예를 들어, 배열의 공간적 지역성은 linked list보다 낫지만, 노드의 추가/삭제가 빈번하게 발생하는 경우에는 linked list가 배열에 비해 우수함
- Linked list의 노드 추가/삭제에 대한 시간 복잡도 O(1)
- 노드의 추가/삭제가 쉬운 장점을 유지하면서 캐시 친화적이고 싶은 linked list를 사용하려면? → 직접 정의한 메모리 풀에서 메모리를 요청하면 됨
이런 최적화를 진행할 때 반드시 분석 도구를 사용하여 캐시의 적중률이 시스템 성능에 병목이 되는지 판단해야 함. 병목이 되지 않으면 굳이 이런 최적화를 할 필요가 없음
5.2.6 다차원 배열 순회
- 배열을 row, column 순서로 순회하면서 값을 모두 더하는데 C언어 역시 row 우선 방식(row major)으로 배열을 저장
- row major: 메모리에 저장할 때 첫번째 행이 첫번째 열부터 마지막 열까지 저장되고, 이어서 두번째 행이 첫번째 열부터 마지막 열까지 저장되는 것을 반복하는 구조
int matrix_summer(int A[M][N])
{
int i, j, sum = 0;
for(i=0; i< M;i++)
{
for(j=0;j<N;j++)
{
sum += A[i][j];
}
}
return sum;
}
- 배열에 행 4개와 열 8개가 있다고 가정 (M이 4, N이 8)
- 캐시가 최대 4개의 int 형식 데이터를 저장할 수 있다고 가정
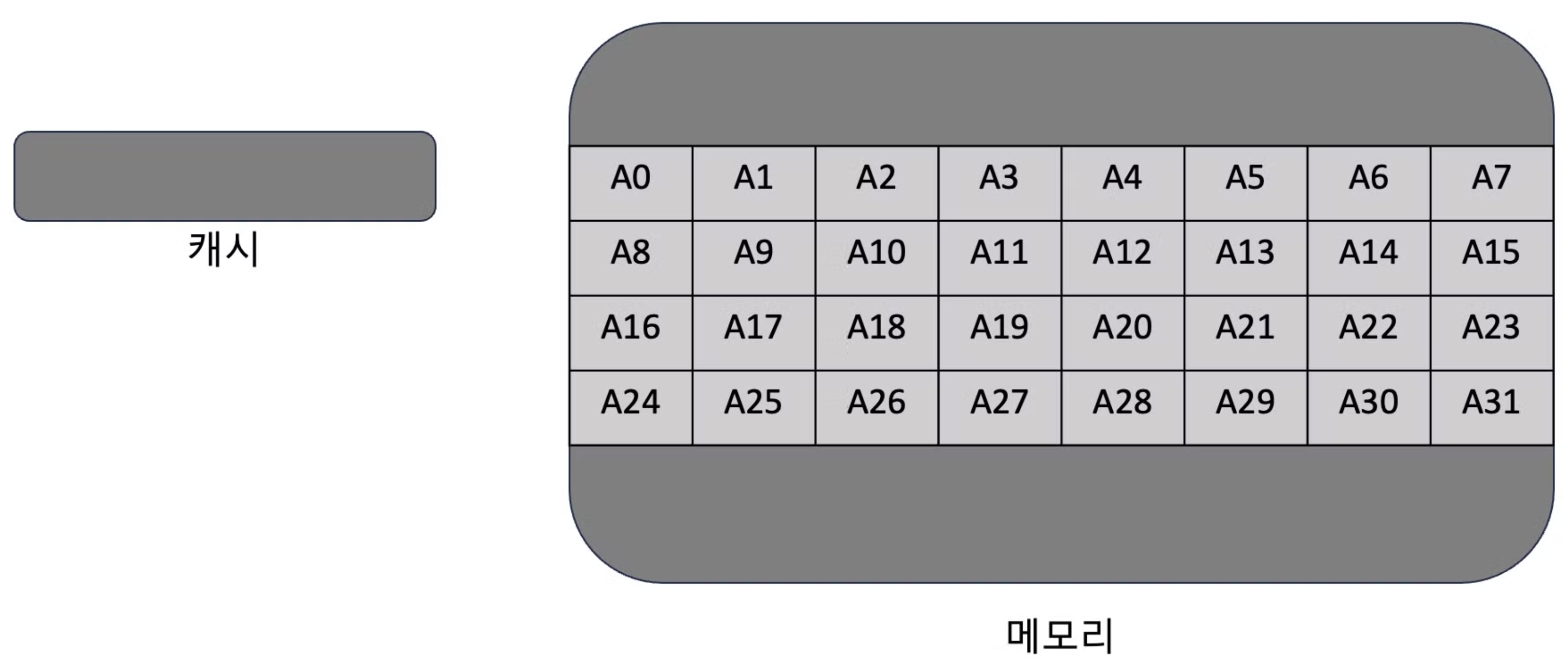
- 순회가 시작되면 캐시에 아직 배열에 대한 데이터가 없기 때문에 캐시는 비어있어 배열 A의 첫번째 요소인 A0에 접근하는 시점에 캐시가 적중할 수 없음 → A0를 포함한 요소 4개가 캐시에 저장됨

- 캐시 준비가 완료되어 A1부터 A3에 접근할 때는 모두 캐시가 적중하기 때문에 메모리에 접근할 필요가 없음

- A4에 접근할 때는 캐시 용량의 제한으로 캐시가 적중할 수 없는데 다시 A4개를 포함한 요소 4개가 캐시에 저장되어 이전 데이터와 교체됨

- 각 행마다 8개 요소들 중 2개를 miss하기 때문에 75% 의 캐시 적중률을 보여줌
이번에는 열 우선 방식으로 접근 (column major)
int matrix_summer(int A[M][N])
{
int i, j, sum = 0;
for(j=0; j< N;j++)
{
for(i=0;i<M;i++)
{
sum += A[i][j];
}
}
return sum;
}
첫번째 요소인 A0에 접근하면 아직 캐시가 적중할 수 없기 때문에 아래와 같이 A0부터 A3까지 캐시에 저장됨

그러나 우리 코드에서 다음에 접근할 요소는 A8이며 이 데이터는 여전히 캐시가 적중할 수 없고 캐시에 A8부터 A11을 저장. 이전 캐시는 사용되지 못함

- 위와 같이 열 우선 방식으로 배열을 순회하면 캐시는 매번 적중에 실패하여 적중률은 0
'OS' 카테고리의 다른 글
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.1 CPU는 어떻게 입출력 작업을 처리할까? (1) (0) | 2024.09.29 |
|---|---|
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch5.3 다중 스레드 성능 방해자 (0) | 2024.09.22 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch5.1 캐시, 어디에나 존재하는 것 (0) | 2024.09.14 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch4.7 CPU 진화론(중): 축소 명령어 집합의 탄생 (0) | 2024.09.08 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch4.6 CPU 진화론(상): 복잡 명령어 집합의 탄생 (0) | 2024.09.08 |