이글은 책 "파이썬 클린 코드" ch2의 내용을 읽고 요약 및 추가한 내용입니다.
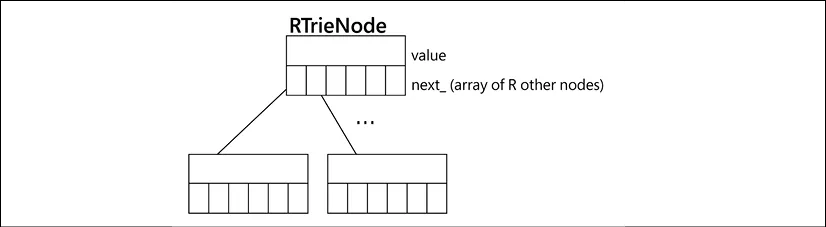
예시: R-Trie 자료 구조에 대한 노드 모델링
- 문자열에 대한 빠른 검색을 위한 자료구조라는 정도로만 알고 넘어가기
- 현재의 문자를 나타내는 value, 다음에 나올 문자를 나타내는 next_ 배열을 가지고 있음
- linked list나 tree 형태와 비슷
from typing import List
from dataclasses import dataclass, field
R = 26
@dataclass
class RTrieNode:
size = R
value: int
next_: List["RTrieNode"] = field(default_factory=lambda: [None] * R)
def __post_init__(self):
if len(self.next_) != self.size:
raise ValueError(f"리스트(next_)의 길이가 유효하지 않음")
- size는 class variable로 모든 객체가 값을 공유
- value는 정수형이지만 기본값이 없으므로 객체 생성시 반드시 값을 정해줘야 함
- next_는 R크기 만큼의 길이를 가진 list로 초기화
- __post_init__은 next_가 원하는 형태로 잘 생성되었는지 확인하는 검증
from typing import List
from dataclasses import dataclass, field
R = 26 # 영어 알파벳
@dataclass
class RTrieNode:
size = R
value: int
next_: List["RTrieNode"] = field(default_factory=list)
def __post_init__(self):
if len(self.next_) != self.size:
raise ValueError(f"리스트(next_)의 길이가 유효하지 않음")
rt_node = RTrieNode(value=0) # ValueError: 리스트(next_)의 길이가 유효하지 않음
이터러블 객체
__iter__ 매직 메소드를 구현한 객체
파이썬의 반복은 이터러블 프로토콜이라는 자체 프로토콜을 사용해 동작
for e in my_object
위 형태로 객체를 반복할 수 있는지 확인하기 위해 파이썬은 고수준에서 아래 두가지 차례로 검사
- 객체가 __next__나 __iter__ 메서드 중 하나를 포함하는지 여부
- 객체가 시퀀스이고 __len__과 __getitem__을 모두 가졌는지 여부
For-loop에 대한 구체적인 과정
my_list = ["사과", "딸기", "바나나"]
for i in my_list:
print(i)- for 문이 시작할 때 my_list의 __iter__()로 iterator를 생성
- 내부적으로 i = __next__() 호출
- StopIteration 예외가 발생하면 반복문 종료
Iterable과 Iterator의 차이
- Iterable: loop에서 반복될 수 있는 python 객체, __iter__() 가 구현되어있어야 함
- Iterator: iterable 객체에서 __iter__() 호출로 생성된 객체로 __iter__()와 __next__()가 있어야하고, iteration 시 현재의 순서를 가지고 있어야 함
이터러블 객체 만들기
객체 반복 시 iter() 함수를 호출하고 이 함수는 해당 객체에 __iter__ 메소드가 있는지 확인
from datetime import timedelta
from datetime import date
class DateRangeIterable:
"""자체 이터레이터 메서드를 가지고 있는 iterable"""
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._present_day = start_date
def __iter__(self):
return self # 객체 자신이 iterable 임을 나타냄
def __next__(self):
if self._present_day >= self.end_date:
raise StopIteration()
today = self._present_day
self._present_day += timedelta(days=1)
return today
for day in DateRangeIterable(date(2024, 6, 1), date(2024, 6, 4)):
print(day)
2024-06-01
2024-06-02
2024-06-03
- for 루프에서 python은 객체의 iter() 함수를 호출하고 이 함수는 __iter__ 매직 메소드를 호출
- self를 반환하면서 객체 자신이 iterable임을 나타냄
- 루프의 각 단계에서마다 자신의 next() 함수를 호출
- next 함수는 다시 __next__ 메소드에게 위임하여 요소를 어떻게 생산하고 하나씩 반환할 것인지 결정
- 더 이상 생산할 것이 없는 경우 파이썬에게 StopIteration 예외를 발생시켜 알려줘야함
⇒ for 루프가 작동하는 원리는 StopIteration 예외가 발생할 때까지 next()를 호출하는 것과 같다
from datetime import timedelta
from datetime import date
class DateRangeIterable:
"""자체 이터레이터 메서드를 가지고 있는 이터러블"""
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._present_day = start_date
def __iter__(self):
return self
def __next__(self):
if self._present_day >= self.end_date:
raise StopIteration()
today = self._present_day
self._present_day += timedelta(days=1)
return today
r = DateRangeIterable(date(2024, 6, 1), date(2024, 6, 4))
print(next(r)) # 2024-06-01
print(next(r)) # 2024-06-02
print(next(r)) # 2024-06-03
print(next(r)) # raise StopIteration()위 예제는 잘 동작하지만 하나의 작은 문제가 있음
max 함수 설명
- iterable한 object를 받아서 그 중 최댓값을 반환하는 내장함수이다
- 숫자형뿐만 아니라 문자열 또한 비교 가능
str1 = 'asdzCda'
print(max(str1)) # z
str2 = ['abc', 'abd']
print(max(str2)) # abd 유니코드가 큰 값
str3 = ['2022-01-01', '2022-01-02']
print(max(str3)) # 2022-01-02
# 숫자로 이루어진 문자열을 비교할 때 각 문자열의 앞 부분을 비교해서 숫자가 큰 것을 출력
r1 = DateRangeIterable(date(2024, 6, 1), date(2024, 6, 4))
a = ", ".join(map(str, r1)) # "2024-06-01, 2024-06-02, 2024-06-03"
print(max(r1))ValueError: max() iterable argument is empty
- 문제가 발생하는 이유는 이터러블 프로토콜이 작동하는 방식 때문
- 이터러블의 __iter__ 메소드는 이터레이터를 반환하고 이 이터레이터를 사용해 반복
- 위의 예제에서 __iter__ 는 self를 반환했지만 호출될 때마다 새로운 이터레이터를 만들 수 있음
- 매번 새로운 DateRangeIterable 인스턴스를 만들어서 해결 가능하지만 __iter__에서 제너레이터(이터레이터 객체)를 사용할 수도 있음
from datetime import timedelta
from datetime import date
class DateRangeIterable:
"""자체 이터레이터 메서드를 가지고 있는 이터러블"""
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._present_day = start_date
def __iter__(self):
current_day = self.start_date
while current_day < self.end_date:
yield current_day
current_day += timedelta(days=1)
def __next__(self):
if self._present_day >= self.end_date:
raise StopIteration()
today = self._present_day
self._present_day += timedelta(days=1)
return today
r1 = DateRangeIterable(date(2024, 6, 1), date(2024, 6, 4))
a = ", ".join(map(str, r1)) # 2024-06-01, 2024-06-02, 2024-06-03
print(max(r1)) # 2024-06-03
- 달라진 점은 각각의 for loop은 __iter__를 호출하고 이는 제너레이터를 생성
⇒ 이러한 형태의 객체를 컨테이너 이터러블(container iterable)이라고 함
다른 방법
- iterable과 iterator 객체를 분리
from datetime import timedelta, date
class DateRangeIterator:
"""Iterator for DateRangeIterable."""
def __init__(self, start_date, end_date):
self.current_date = start_date
self.end_date = end_date
def __iter__(self):
return self
def __next__(self):
if self.current_date >= self.end_date:
raise StopIteration()
today = self.current_date
self.current_date += timedelta(days=1)
return today
class DateRangeIterable:
"""Iterable for a range of dates."""
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
def __iter__(self):
return DateRangeIterator(self.start_date, self.end_date)
r1 = DateRangeIterable(date(2024, 6, 1), date(2024, 6, 4))
# Using join with map
print(", ".join(map(str, r1))) # Output: 2024-06-01, 2024-06-02, 2024-06-03
# Using max
print(max(r1)) # Output: 2024-06-03
- DateRangeIterable 에서 __iter__가 호출될 때 마다 새로운 Iterator 를 생성할 수도 있음
시퀀스 만들기
객체에 __iter__ 메소드를 정의하지 않았지만 반복하기를 원하는 경우도 있음
객체에 __iter__ 가 정의되어 있지 않으면 __getitem__을 찾고 없으면 TypeError를 발생시킴
시퀀스는 __len__과 __getitem__을 구현하고 첫번째 인덱스0부터 시작하여 포함된 요소를 한 번에 하나씩 가져올 수 있어야 함
이터러블 객체는 메모리를 적게 사용한다는 장점이 있음
- n번째 요소를 얻고 싶다면 도달할 때까지 n번 반복해야하는 단점이 있음 (시간복잡도: O(n))
⇒CPU 메모리 사이의 trade-off
__iter__, __getitem__ 모두 없는 경우
from datetime import timedelta, date
class DateRangeSequence:
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._range = self._create_range()
def _create_range(self):
days = []
current_day = self.start_date
while current_day < self.end_date:
days.append(current_day)
current_day += timedelta(days=1)
return days
# def __getitem__(self, day_no):
# return self._range[day_no]
def __len__(self):
return len(self._range)
s1 = DateRangeSequence(date(2022, 1, 1), date(2022, 1, 5))
for day in s1:
print(day)TypeError: 'DateRangeSequence' object is not iterable
__getitem__있는 경우
from datetime import timedelta, date
class DateRangeSequence:
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self._range = self._create_range()
def _create_range(self):
days = []
current_day = self.start_date
while current_day < self.end_date:
days.append(current_day)
current_day += timedelta(days=1)
return days
def __getitem__(self, day_no):
return self._range[day_no]
def __len__(self):
return len(self._range)
s1 = DateRangeSequence(date(2022, 1, 1), date(2022, 1, 5))
for day in s1:
print(day)
2022-01-01
2022-01-02
2022-01-03
2022-01-04
- __iter__ 없어도 for loop에 사용할 수 있음
컨테이너 객체
__contains__ 메서드를 구현한 객체. 일반적으로 boolean 값을 반환하고 이 메서드는 파이썬에서 in 키워드가 발견될 때 호출됨
element in container
위 코드를 파이썬은 아래와 같이 해석 (잘활용하면 가독성이 정말 높아짐)
container.__contains_(element)
def mark_coordinate(grid, coord):
if 0<= coord.x < grid.width and 0<= coord.y < grid.height:
grid[coord] = MARKED- grid내에 coord 좌표가 포함되는지 여부를 확인하는 코드
Grid 객체 스스로 특정 좌표가 자신의 영역안에 포함되는지 여부를 판단할 수는 없을까? 더 작은 객체 (Boundaries)에 위임하면 어떨까?
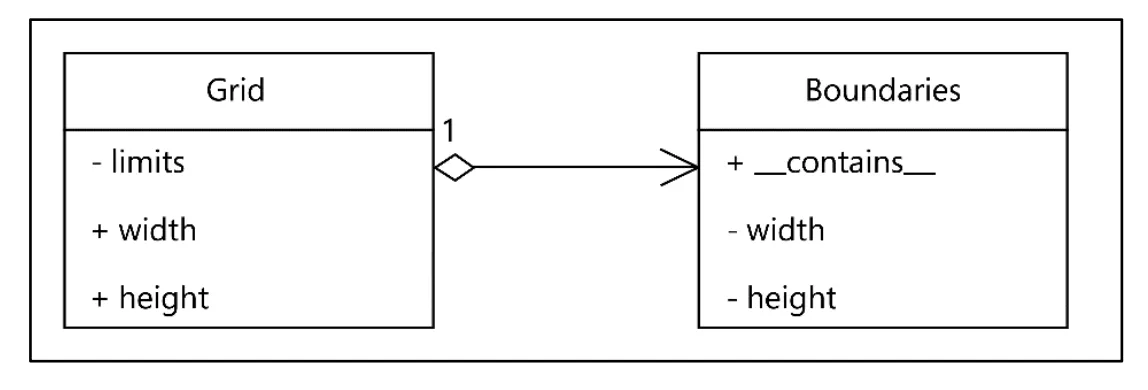
- 컴포지션을 사용하여 포함관계를 표현하고 다른 클래스에 책임을 분배하고 컨테이너 매직 메소드를 사용
class Boundaries:
def __init__(self, width, height):
self.width = width
self.height = height
def __contains__(self, coord):
x, y = coord
return 0 <= x < self.width and 0 <= y < self.height
class Grid:
def __init__(self, width, height):
self.width = width
self.height = height
self.limits = Boundaries(width, height)
def __contains__(self, coord):
return coord in self.limits
Composition 관계 사용 전
def mark_coordinate(grid, coord):
if 0<= coord.x < grid.width and 0<= coord.y < grid.height:
grid[coord] = MARKEDComposition 관계 사용 후
def mark_coordinate(grid, coord):
if coord in grid:
grid[coord] = MARKED
객체의 동적인 생성
__getattr__ 매직 메소드를 사용하면 객체가 속성에 접근하는 방법을 제어할 수 있음
myobject.myattribute 형태로 객체의 속성에 접근하려면 instance의 속성 정보를 가지고 __dict__에 myattribute가 있는지 검색.
- 해당 이름의 속성이 있으면 __getattribute__메소드를 호출
- 없는 경우 조회하려는 속성(myattribute) 이름을 파라미터로 __getattr__ 호출
class DynamicAttributes:
def __init__(self, attribute):
self.attribute = attribute
def __getattr__(self, attr):
if attr.startswith("fallback_"):
name = attr.replace("fallback_", "")
return f"[fallback resolved] {name}"
raise AttributeError(f"{self.__class__.__name__}에는 {attr} 속성이 없음")
dyn = DynamicAttributes("value")
print(dyn.attribute) # value
print(dyn.fallback_test) # [fallback resolved] test
dyn.__dict__["fallback_new"] = "new value" # dict로 직접 인스턴스에 추가
print(dyn.fallback_new) # new value
print(getattr(dyn, "something", "default")) # default
호출형 객체(callable)
- 함수처럼 동작하는 객체를 만들면 데코레이터 등 편리하게 사용 가능
- __call__ 매직 메소드가 호출됨
from collections import defaultdict
class CallCount:
def __init__(self):
self._counts = defaultdict(int)
def __call__(self, argument):
self._counts[argument] += 1
return self._counts[argument]
cc = CallCount()
print(cc(1)) # 1
print(cc(2)) # 1
print(cc(1)) # 2
print(cc(1)) # 3
print(cc("something")) # 1
print(callable(cc)) # True
매직 메소드 요약
사용 예 매직 메서드 비고
| 사용예 | 매직 메소드 | 비고 |
| obj[key] obj[i:j] obj[i:j:k] |
__getitem__(key) | 첨자형(subscriptable) 객체 |
| with obj: ... | __enter__ / __exit__ | 컨텍스트 관리자 |
| for i in obj: ... | __iter__ / __next__ __len__ / __getitem__ |
이터러블 객체 시퀀스 |
| obj.<attribute> | __getattr__ | 동적 속성 조회 |
| obj(*args, **kwargs) | __call__(*arg, **kwargs) | 호출형(callable) 객체 |
- 이러한 매직 메소드를 올바르게 구현하고 같이 구현해야 하는 조합이 뭔지 확인하는 가장 좋은 방법은 collections.abc 모듈에서 정의된 추상클래스를 상속하는 것
파이썬에서 유의할 점
mutable 파라미터의 기본 값
def wrong_user_display(user_metadata: dict = {"name": "John", "age": 30}):
name = user_metadata.pop("name")
age = user_metadata.pop("age")
return f"{name} ({age})"
2가지 문제 존재
- 변경 가능한 기본 값을 사용한 것. 함수의 본문에서 수정 가능한 객체의 값을 직접 수정하여 부작용 발생
- 기본 인자
- 함수에 인자를 사용하지 않고 호출할 경우 처음에만 정상 동작
- 파이썬 인터프리터는 함수의 정의에서 dictionary를 발견하면 딱 한번만 생성하기 때문에 pop하는 순간 해당 key, value는 없어짐
print(wrong_user_display()) # John (30)
print(wrong_user_display()) # KeyError: 'name'수정방법은?
- 기본 초기 값을 None으로 하고 함수 본문에서 기본 값을 할당
def wrong_user_display(user_metadata: dict = None):
user_metadata = user_metadata or {"name": "John", "age": 30}
name = user_metadata.pop("name")
age = user_metadata.pop("age")
return f"{name} ({age})"내장(built-in) 타입 확장
- 내장 타입을 확장하는 올바른 방법은 list, dict 등을 직접 상속받는 것이 아니라 collections 모듈을 상속받는 것
- collections.UserDict
- collections.UserList
- 파이썬을 C로 구현한 CPython 코드가 내부에서 스스로 연관된 부분을 모두 찾아서 업데이트 해주지 않기 때문
class BadList(list):
def __getitem__(self, index):
value = super().__getitem__(index)
if index % 2 == 0:
prefix = "짝수"
else:
prefix = "홀수"
return f"[{prefix}] {value}"
b1 = BadList((0, 1, 2, 3, 4, 5))
print(b1)
print(b1[0]) # [짝수] 0
print(b1[1]) # [홀수] 1
print("".join(b1)) # TypeError: sequence item 0: expected str instance, int foundfrom collections import UserList
class BadList(UserList):
def __getitem__(self, index):
value = super().__getitem__(index)
if index % 2 == 0:
prefix = "짝수"
else:
prefix = "홀수"
return f"[{prefix}] {value}"
b1 = BadList((0, 1, 2, 3, 4, 5))
print(b1)
print(b1[0]) # [짝수] 0
print(b1[1]) # [홀수] 1
print("".join(b1)) # [짝수] 0[홀수] 1[짝수] 2[홀수] 3[짝수] 4[홀수] 5
'Python' 카테고리의 다른 글
| [책리뷰] CPython 파헤치기 4장. 파이썬 언어와 문법 (0) | 2024.11.10 |
|---|---|
| pathlib 모듈 (0) | 2024.10.20 |
| [책리뷰] 파이썬 클린 코드 Chapter 2. Pythonic 코드 (1) (0) | 2024.09.29 |
| super() (0) | 2024.09.15 |
| The Walrus Operator: Python's Assignment Expressions (바다코끼리 연산자) (0) | 2024.08.31 |