
반응형
event-based concurrency를 이용한 event-driven programming은 아래 2가지가 필요
- 이벤트: 네트워크 데이터의 수신 여부, 파일의 읽기 및 쓰기 가능 여부 등의 관심 대상
- 이벤트를 처리하는 함수: 이벤트 핸들러(event handler) 라고 함
while (true)
{
event = getEvent(); // 이벤트 수신 대기
handler(event); // 이벤트 처리
}
해결해야 할 2가지 문제
- 첫번째 문제: getEvent 같은 함수 하나가 어떻게 여러 이벤트를 가져올 수 있나?
- 두번째 문제: 이벤트를 처리하는 handler 함수가 반드시 이벤트 순환과 동일한 스레드에서 실행되어야 하나?
첫번째 문제: 이벤트 소스와 입출력 다중화
- 리눅스와 UNIX 세계에서 모든 것이 파일로 취급됨
- 프로그램은 file descriptor(fd)를 사용하여 입출력 작업을 실행(socket도 예외 아님)
동시에 fd 여러개를 처리하기 위해서는?
ex) 사용자 연결이 10개고 이에 대응하는 소켓 서술자가 열개 있는 서버가 데이터 수신 대기중
recv(fd1, buf1);
recv(fd2, buf2);
recv(fd3, buf3);
recv(fd4, buf4);
- 첫번째 줄 코드에서 사용자가 데이터를 보내지 않는한 recv(fd1, buf1) 는 반환되지 않으므로 서버가 두 번째 사용자의 데이터를 수신하고 처리할 기회가 사라짐
더 좋은 방법은?
- 운영체제에게 내용을 전달하는 작동 방식 사용
- ‘저 대신 소켓 서술자 열 개를 감시하고 있다가, 데이터가 들어오면 저에게 알려주세요’
- 입출력 다중화라고 하며 리눅스 세계에서 가장 유명한 것이 epoll
// epoll 생성
epoll_fd = epoll_create();
// 서술자를 epoll이 처리하도록 지정
Epoll_ctl(epoll_fd, fd1, fd2, fd3, fd4, ...);
while(1)
{
int n = epoll_wait(epoll_fd); // getEvent 역할로 지속적으로 다양한 이벤트 제공
for(i=0;i<n;i++)
{
// 특정 이벤트 처리
}
}
- epoll은 이벤트 순환(event loop)을 위해 탄생했음

위 사진처럼 epoll을 통해 이벤트 소스 문제가 해결됨
두번쨰 문제: 이벤트 순환과 다중 스레드
이벤트 핸들러에 2가지 특징이 있다고 가정
- 입출력 작업이 전혀 없음
- 처리함수가 간단해서 소요시간이 매우 짧음
이 경우 간단히 모든 요청을 단일스레드에서 순차적으로 처리가능

하지만 CPU시간을 많이 소모하는 사용자 요청을 처리해야 한다면?
- 요청의 처리 속도를 높이고 다중 코어를 최대한 사용하려면 다중 스레드의 도움이 필요

- 이벤트 핸들러는 더 이상 이벤트 순환과 동일한 스레드에서 실행되지 않고 독립적인 스레드에 배치됨
- 이벤트 순환은 요청을 수신하면 간단한 처리 후 바로 각각의 작업자 스레드에 분배
- 작업자 스레드를 thread pool로 구현하는 것도 가능
⇒ 이러한 설계 방법을 reactor pattern(반응자 패턴)이라고 부름
카페/음식점에서 주문 받는 사람(이벤트 순환)과 요리하는 사람(작업자 스레드)을 다르게 운영하는 것과 같다.
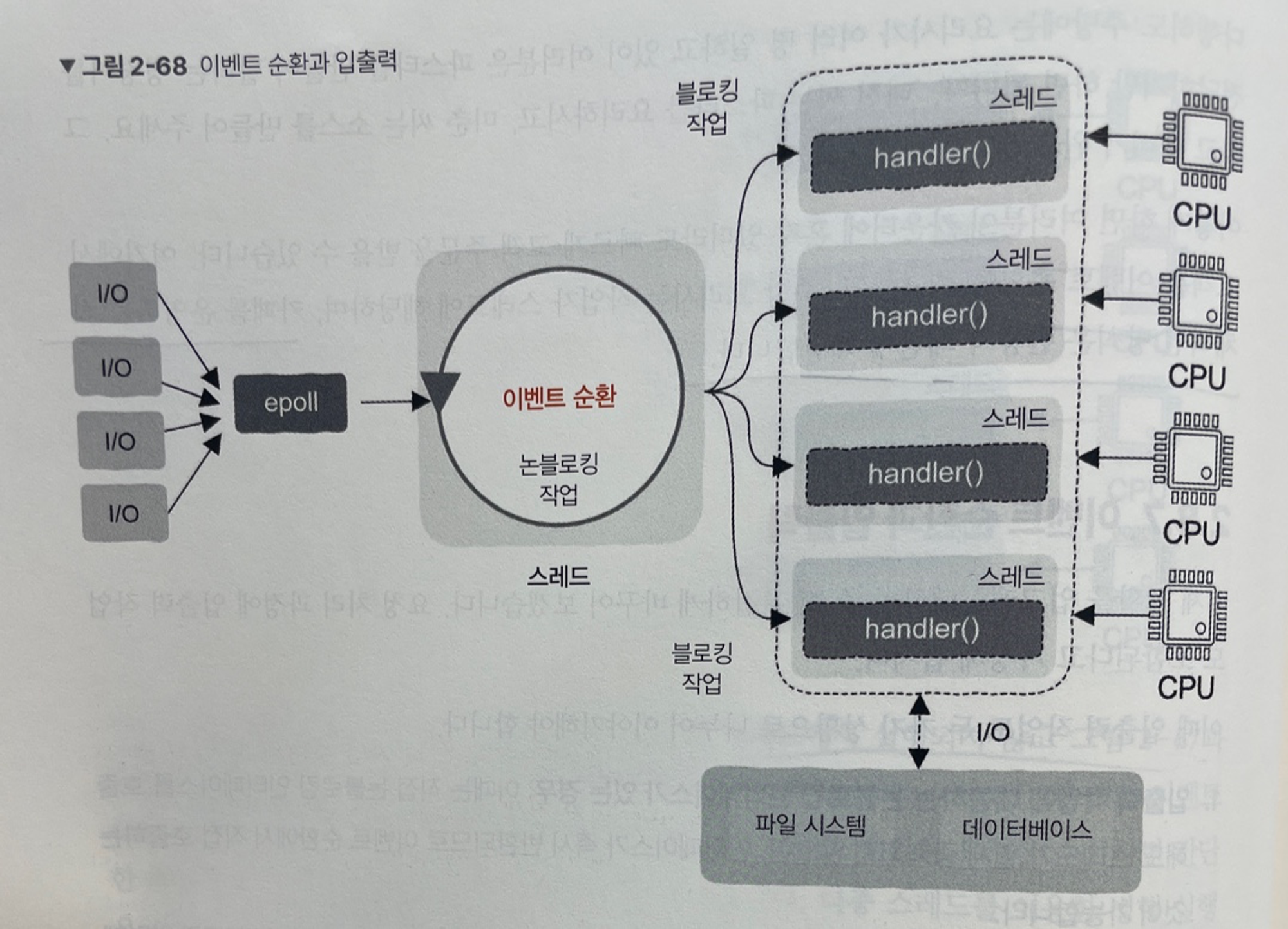
이벤트 순환과 입출력
요청 처리 과정에 입출력 작업도 포함된다고 가정하면 2가지 상황 발생 가능
- 입출력 작업에 대응하는 논 블로킹 인터페이스가 있는 경우
- 직접 논블로킹 인터페이스를 호출해도 스레드가 일시 중지 않고, 인터페이스가 즉시 반환되므로 event loop에서 직접 호출하는 것이 가능
- 입출력 작업에 블로킹 인터페이스만 있는 경우
- 이때는 절대로 event loop에서 어떤 블로킹 인터페이스도 호출하면 안됨
- 호출하게 된다면 순환 스레드가 일지 중지될 수 있음
- 블로킹 입출력 호출이 포함된 작업은 작업자 스레드에 전달해야 함
비동기와 콜백 함수
- 비지니스가 발전하면서 서버 기능은 점점 복잡해지고 여러 서버가 조합되어 하나의 사용자 요청을 처리
void handler(request)
{
A;
B;
GetUserInfo(request, response); // A 서버에 요청 후 응답을 받아 매게변수 response에 저장
C;
D;
GetQueryInfo(request, response); // B 서버에 요청 후 응답을 받아 매게변수 response에 저장
E;
F;
GetStorkInfo(request, response); // C 서버에 요청
G;
H;
}- Get 으로 시작하는 호출은 모두 블로킹 호출로 CPU 리소스를 최대한 활용하지 못할 가능성이 매우 높음 → 비동기 호출로 수정 필요
void handler_after_GetStorkInfo(response)
{
G;
H;
}
void handler_after_GetQueryInfo(response)
{
E;
F;
GetStorkInfo(request, handler_after_GetStorkInfo); // 서버 C에 요청
}
void handler_after_GetUserInfo(response)
{
C;
D;
GetQueryInfo(request, hanlder_after_GetQueryInfo); // 서버 B에 요청
}
void handler(request)
{
A;
B;
GetUserInfo(request, handler_after_GetUserInfo); // 서버 A에 요청
}- 저 프로세스가 4개로 분할되었고 콜백 안에 콜백이 포함되어있음
- 사용자 서비스가 더 많아지면 관리가 불가능한 코드 형태
비 동기 프로그래밍 효율성과 동기 프로그래밍의 단순성을 결합할 수 있다면? → 코루틴
코루틴: 동기 방식의 비동기 프로그래밍
- 언어나 프레임워크가 코루틴을 지원하는 경우 handler 함수가 코루틴에서 실행되도록 할 수 있음
- 코드 구현은 여전히 동기로 작성되지만 yield로 CPU제어권을 반환할 수 있음
- 코루틴이 일시 중지 되더라도 작업자 스레드가 블로킹되지 않음 (코루틴과 스레드의 차이)
- 코루틴이 일시중지되면 작업자 스레드는 다른 코루틴을 실행하기 위해 전환됨
- 일시 중지된 코루틴에 할당된 사용자 서비스가 응답한 후 그 처리 결과를 반환하면 다시 준비상태가 되어 스케쥴링 차례가 돌아오길 기다림
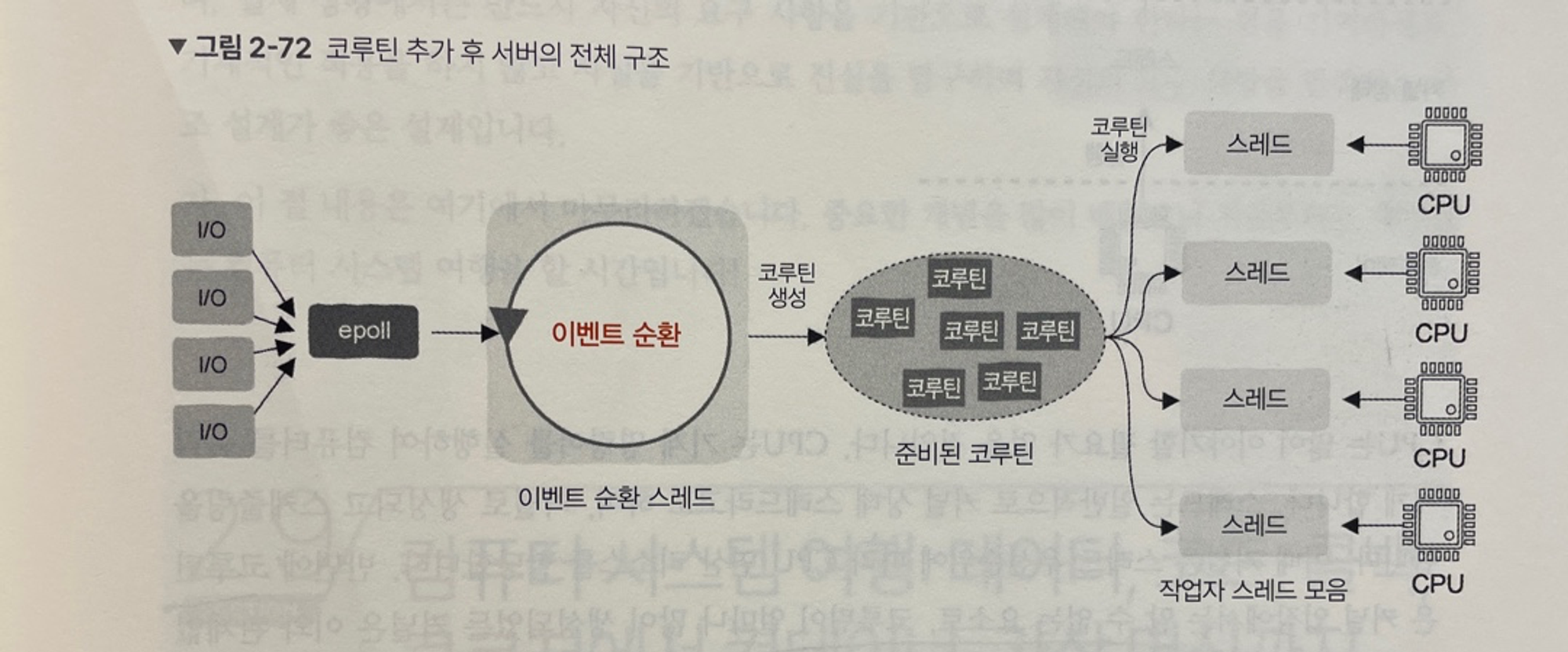
- 이벤트 loop은 요청을 받은 후 우리가 구현한 handler 함수를 코루틴에 담아 스케쥴링과 실행을 위해 각 작업자 스레드에 배포
- 작업자 스레드는 코루틴을 획든한 후 진입 함수인 handler 를 실행
- 어떤 코루틴이 CPU의 제어권을 반환하면 작업자 스레드는 다른 코루틴을 실행
- 비록 코루틴이 블로킹 방식이더라도 작업자 스레드는 블로킹되지 않음
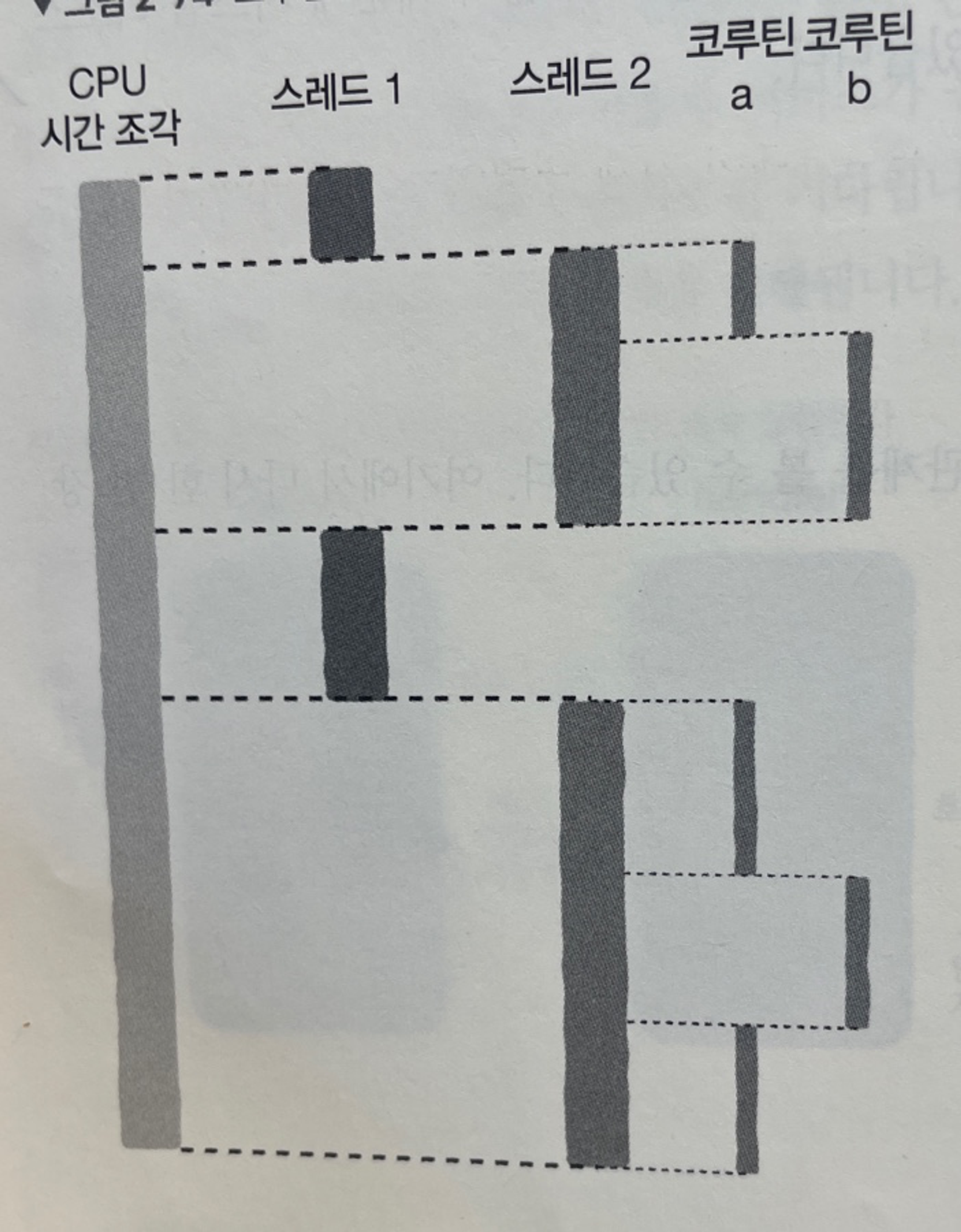
- 스레드는 일반적으로 커널 상태 스레드라고 부름
- 커널로 생성되고 스케쥴링을 함
- 커널은 스레드 우선순위에 따라 CPU 연산 리소스를 할당
- 코루틴은 커널 입장에서는 알 수 없는 요소로 코루틴 수는 커널과 무관하게 스레드에 따라 CPU시간 할당
- 코루틴을 사용자 상태 스레드라고도 함
반응형
'OS' 카테고리의 다른 글
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch3.2 -3.3 메모리 내의 프로세스 (0) | 2024.08.25 |
|---|---|
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch3.1 메모리의 본질, 포인터와 참조 (0) | 2024.08.25 |
| 블로킹/논블로킹 (0) | 2024.08.10 |
| 동기/비동기 (0) | 2024.08.10 |
| 파일 시스템 (0) | 2024.07.28 |