반응형
이 글은 책 컴퓨터 밑바닥의 비밀 chapter 5.3의 내용을 읽고 요약한 글입니다.
5.3.1 캐시와 메모리 상호 작용의 기본 단위: 캐시 라인
캐시 라인(Cache line)이란?
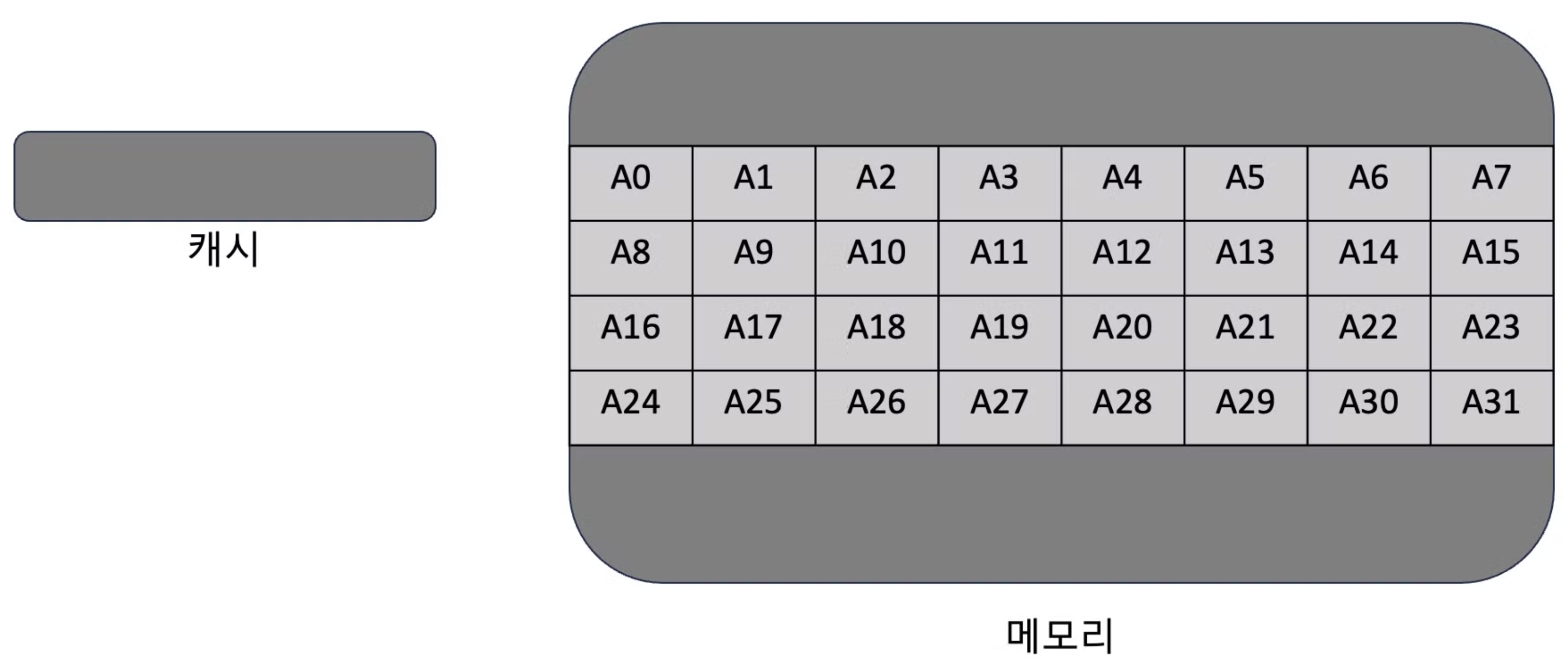
- 프로그램이 어떤 데이터에 접근하면 다음에도 인접한 데이터에 접근할 가능성이 높으므로 데이터가 있는 곳의 ‘묶음’ 데이터를 캐시에 저장하는데 이 ‘묶음’을 캐시 라인이라고 함
캐시와 메모리가 상호 작용하는 기본 단위는 캐시 라인이며, 이 크기는 일반적으로 64 바이트임.
캐시가 적중하지 모샇는 경우 이 묶음 데이터가 캐시에 저장됨.
5.3.2 첫번째 성능 방해자: 캐시 튕김 문제
아래 2가지 코드가 있음
첫번째 코드
atomic<int> a;
void threadf()
{
for(int i=0;i<500000000;i++)
{
++a;
}
}
void run()
{
thread t1 = thread(threadf);
thread t2 = thread(threadf);
t1.join();
t2.join();
}- 2개의 스레드를 시작하는데 각 스레드를 전역변수 a값을 1씩 5억번씩 증가
두번째 코드
atomic<int> a;
void run()
{
for(int i=0;i<1000000000;i++)
{
++a;
}
}- 단일 스레드로 전역변수 a값을 1씩 10억번씩 증가
어떤 코드의 속도가 더 빠를까?
- 다중 코어 컴퓨터 기준 첫번째 프로그램의 실행시간이 16초, 두번째 실행시간은 8초에 불과했음
- 병렬 계산임에도 다중 스레드가 단일 스레드보다 느린 이유는?
- 리눅스의 perf 도구를 사용하여 두 코드를 분석할 수 있음
- “perf stat” 명령어는 프로그램 실행 시에 나타나는 각종 주요 정보의 통계를 보여주는데 여러 항목 중 insn per cycle 항목에서 차이를 보임
insn per cycle
- 하나의 클럭 주기에 CPU가 실행하는 프로그램에서 기계 명령어를 몇개 실행하는지 알려줌
- 다중 스레드는 0.15, 단일 스레드는 0.6으로 단일 스레드 프로그램에서 하나의 클럭 주기 동안 기계 명령어나 4배나 다 많이 실행되었음. 이유는?
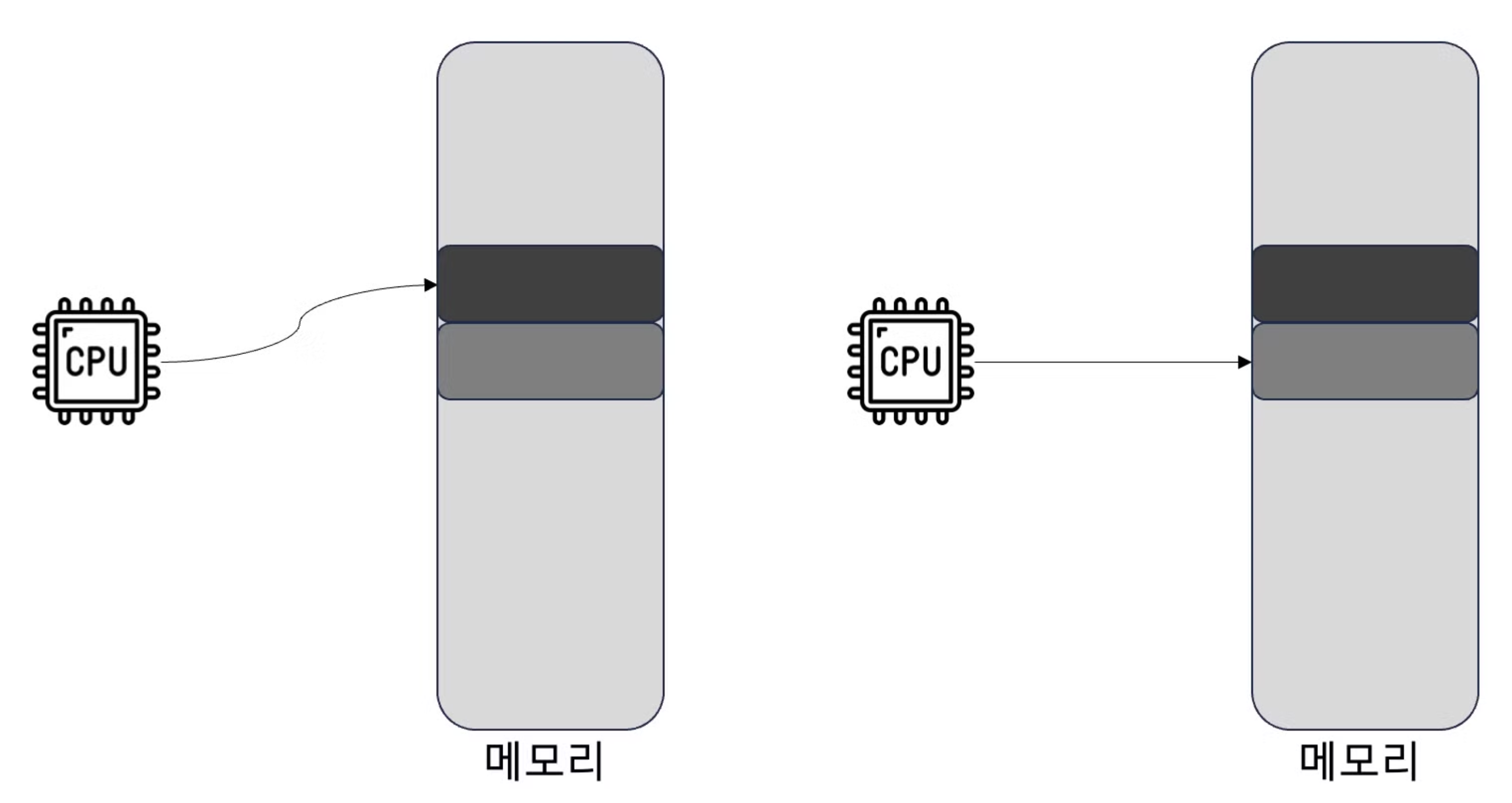
캐시 일관성을 보장하기 위해 두 코어의 캐시에서 전역 변수 a처럼 동일한 변수가 사용될 때는 두 캐시에 모두 저장됨

두 스레드는 모두 해당 변수에 1을 더해야 함. 이때 첫번 째 스레드가 아래 그림과 같이 a 변수에 덧셈 연산을 실행하기 시작한다면, 다른 cpu 캐시의 a 변수를 무효화(invalidation) 해야 함 → 캐시 튕김 발생

- 캐시와 메모리의 불일치 문제를 방지 하기 위해 메모리의 a 변수 값도 업데이트
- 동시에 다른 cpu 캐시에 있는 a 변수 값을 무효화

1. 아래 cpu의 캐시가 무효화되어 어쩔 수 없이 메모리에서 직접 a변수 값을 읽어야 함

- 아래 cpu도 a 변수에 1을 더하고 캐시이 일관성을 보장하기 위해 메모리에 a 변수 값을 업데이트
- 위 cpu 캐시의 a 변수 무효화 → 또 다시 캐시 튕김이 발생
이와 같이 각 cpu의 캐시가 끊임없이 서로 상대 캐시를 무효화하면서 튕겨냄
⇒ 여러 스레드 사이에 데이터 공유를 피할 수 있다면 가능한 피해야 함을 의미
5.3.3 두번째 성능 방해자: 거짓 공유 문제
첫번째 코드
struct data
{
int a;
int b;
};
struct data global_data;
void add_a()
{
for(int i=0;i<50000000;i++)
{
++ global_data.a;
}
}
void add_b()
{
for(int i=0;i<50000000;i++)
{
++ global_data.b;
}
}
void run()
{
thread t1 = thread(add_a);
thread t2 = thread(add_b);
t1.join();
t2.join();
}- 스레드 2개를 시작한 후 구조체의 a 변수와 b 변수를 1씩 5억번 증가시킴
두번째 프로그램
void run()
{
for(int i=0;i<50000000;i++)
{
++global_data.a;
}
for(int i=0;i<50000000;i++)
{
++global_data.b;
}
}- 단일 스레드로 동일하게 a 변수와 b 변수를 1씩 5억 번 증가시킴
- 첫번째 코드가 두 변수를 공유하지 않고 다중 쓰레드 프로그램이니 더 빠르게 실행될 것이라고 예상할 수 있음 → 사실을 그렇지 않음
- 사실 두 스레드는 어떤 변수도 공유하지 않지만 이 두 변수는 동일한 캐시 라인(cache line)에 있을 가능성이 매우 높아 캐시 튕김 문제가 발생할 수 있음 ⇒ 거짓 공유(false sharing)이라고 함
개선하는 방법으로 두 변수가 같은 캐시라인에 있지 않도록 하는 것인데 아래처럼 구조체를 구성하면 가능
struct data
{
int a;
int arr[16];
int b;
}
- 다중 코어 컴퓨터에서 캐시 라인 크기가 64바이트이며, arr[16]을 통해 int 형식의 배열을 채우면 a 변수와 b변수는 다른 캐시라인에 있게 됨.
반응형
'OS' 카테고리의 다른 글
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.1 CPU는 어떻게 입출력 작업을 처리할까? (2) (0) | 2024.10.06 |
|---|---|
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch6.1 CPU는 어떻게 입출력 작업을 처리할까? (1) (0) | 2024.09.29 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch5.2 어떻게 캐시 친화적인 프로그램을 작성할까? (0) | 2024.09.15 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch5.1 캐시, 어디에나 존재하는 것 (0) | 2024.09.14 |
| [책리뷰] 컴퓨터 밑바닥의 비밀: ch4.7 CPU 진화론(중): 축소 명령어 집합의 탄생 (0) | 2024.09.08 |