본 글은 책 "혼자 공부하는 컴퓨터 구조+운영체제" 의 Chapter 10. 프로세스와 스레드 부분을 읽고 정리한 내용입니다.
10-1. 프로세스 개요
- 실행중인 프로그램
- 실행되기 전까지는 보조기억장치에 있는 데이터 덩어리일 뿐이지만, 메모리에 적재되고 실행되는 순간 프로세스가 됨

ps 명령어로 프로세스 직접 확인하기
- ps: process status
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
0 1 0 0 Tue11PM ?? 3:49.05 /sbin/launchd
0 298 1 0 Tue11PM ?? 2:45.95 /usr/libexec/logd
0 299 1 0 Tue11PM ?? 0:00.11 /usr/libexec/smd
0 300 1 0 Tue11PM ?? 0:09.75 /usr/libexec/UserEventAgent (System)
- -e: 커널 프로세스를 제외한 모든 프로세스를 출력
- -f: 출력을 풀 포맷으로 표기 (유닉스 스타일) UID, PID , PPID 등이 함께 표시
- UID: Process owner의 user id
프로세스 종류
- 포그라운드 프로세스(Foreground process): 사용자가 보는 앞에서 실행되는 프로세스
- 백그라운드 프로세스(Background process): 뒷편에서 실행되는 프로세스로 사용자와 직접 상호작용 할 수있는 백그라운드 프로세스도 있지만 묵묵히 정해진 일만 수행하는 백그라운드 프로세스도 있음
- daemon: 유닉스 체계의 운영체제에서 부르는 백그라운드 프로세스
- service: windows 에서 부르는 백그라운드 프로세스
프로세스 제어 블록
- 프로세스들은 차례대로 돌아가며 한정된 시간만큼만 CPU를 이용
- 시간이 끝났음을 알리는 인터럽트(타이머 인터럽트)가 발생하면 프로세스 자신의 차례를 양보하고 다음 차례가 올때까지 기다림

프로세스 제어 블록 (Process Control Block, PCB)
- 프로세스와 관련된 정보를 저장하는 자료구조 like 상품에 달린 태그 (커널 영역에 생성됨)
- 운영체제는 빠르게 번갈아 수행되는 프로세스의 실행 순서를 관리하고 CPU등의 자원을 분배하기 위해 이용
- 프로세스 생성 시에 만들어지고 실행이 끝나면 폐기됨
PCB에 담기는 정보
- Process ID (PID)
- 특정 프로세스를 식별하기 위해 부여하는 고유한 번호
- 레지스터 값
- 프로세스는 자신의 실행차례가 돌아오면 이전까지 사용했던 레지스터의 중간값들을 모두 복원해서 이전까지 진행했던 작업들을 그대로 이어 실행. (프로그램 카운터, 스택 포인터)
- 프로세스 상태
- 입출력장치를 사용하기 위해 기다리는 상태인지, CPU 사용을 위해 기다리는 상태인지, CPU 이용중인지 등
- CPU 스케쥴링 정보
- 언제, 어떤 순서로 CPU를 할당받았는지에 대한 정보
- 메모리 관리 정보
- 프로세스가 어느 주소에 저장되어 있는지에 대한 정보
- 베이스 레지스터, 한계 레지스터 값, 페이지 테이블 정보(14장)
- 사용한 파일과 입출력장치 목록
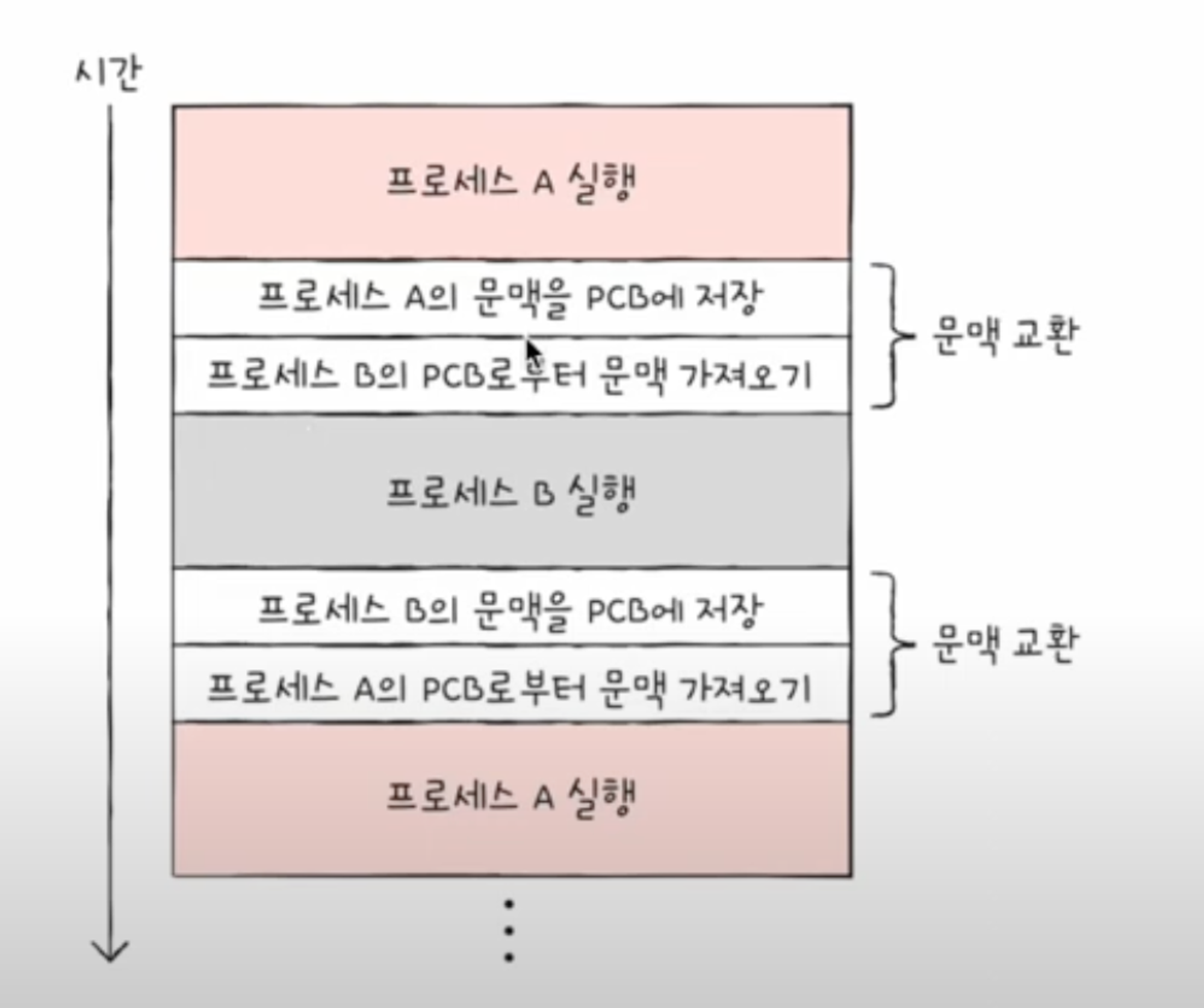
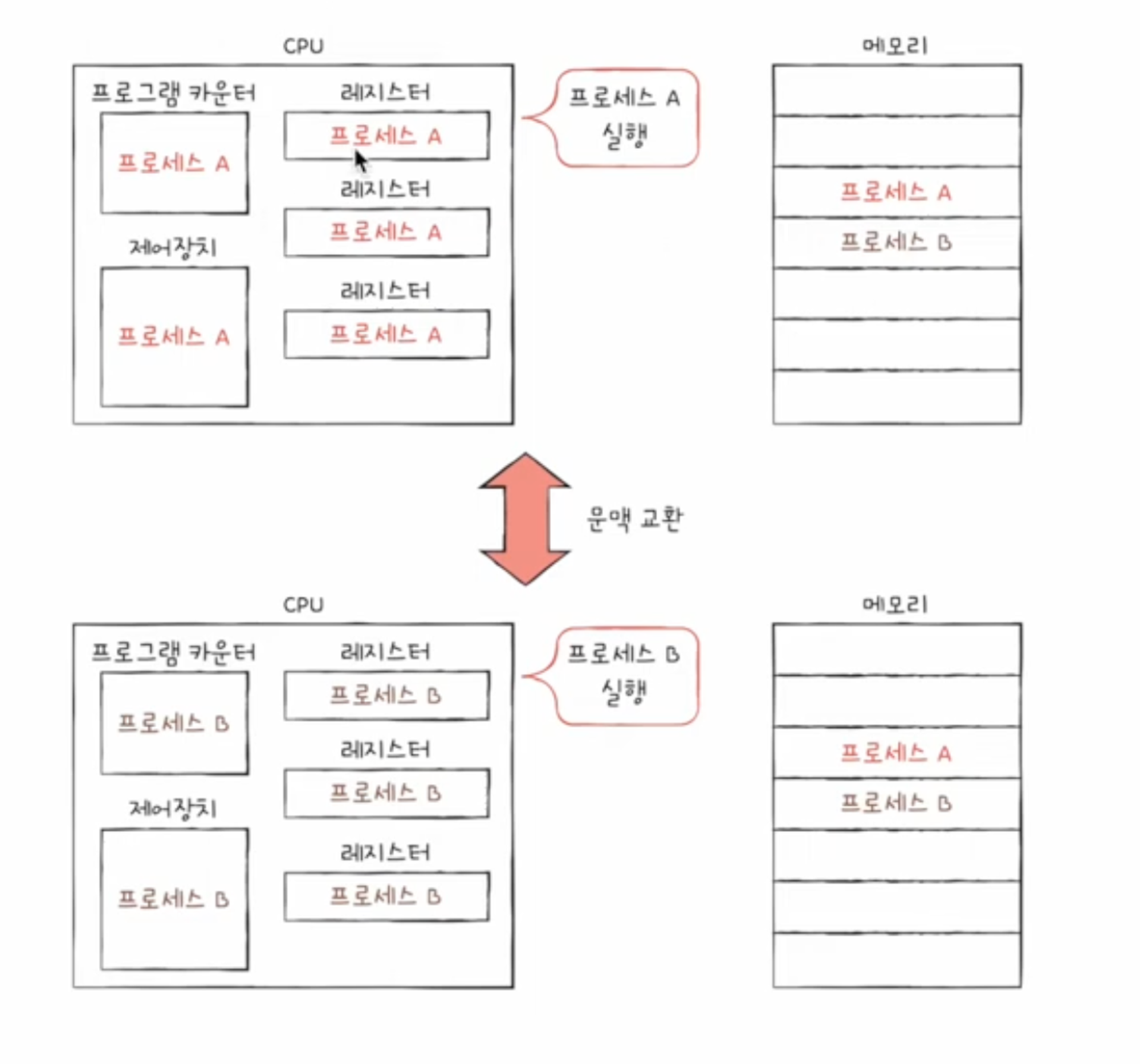
문맥 교환(Context Switch)
- 한 프로세스 → 다른 프로세스로 실행 순서가 넘어가면?
문맥: 하나의 프로세스 수행을 재개하기 위해 기억해야 할 정보로 PCB에 표현되어있음
⇒ 기존의 실행중인 context를 백업하고 새로운 프로세스 실행을 위해 context를 복구하는 과정
- 여러 프로세스가 끊임없이 빠르게 번갈아가며 실행되는 원리
프로세스의 메모리 영역

- 프로세스가 생성되면 커널 영역에 PCB가 생성됨
- 사용자 영역에는?
- 코드 영역
- 데이터 영역
- 힙 영역
- 스택 영역
코드 영역 (code segment)
- 텍스트 영역이라고도 부르고 기계어로 이루어진 명령어가 저장됨
- 데이터가 아닌 CPU가 실행할 명령어가 담겨 있기 때문에 쓰기가 금지됨 (read-only)
데이터 영역
- 프로그램이 실행되는 동안 유지할 데이터가 저장되는 공간
- EX) 전역 변수 (Global variable)
코드 영역과 데이터 영역은 크기가 고정된 영역이라는 점에서 정적 할당 영역이라고도 부름
- 동적 할당 영역: 힙 & 스택 영역으로 프로세스 실행 과정에서 그 크기가 변할 수 있는 영역
힙 영역 (heap segment)
- 프로그래머가 직접 할당할 수 있는 저장 공간
- 프로그래밍 과정에서 메모리 공간을 할당했다면 언젠가는 반환해야하는 공간
- 반환하지 않으면 메모리 내에 계속 남아 메모리 낭비를 초래 ⇒ memory leak
스택 영역 (Stack segment)
- 데이터를 일시적으로 저장하는 공간
- 데이터 영역에 담기는 값과 달리 잠깐 쓰다가 말 값들이 저장되는 공간 (ex) 매개변수, 지역변수)
힙 영역과 스택 영역은 실시간으로 그 크기가 변할 수 있기 때문에 동적 할당 영역이라고 부름
- 힙: 낮은 주소 → 높은 주소
- 스택: 높은 주소 → 낮은 주소

10-2. 프로세스 상태와 계층 구조
프로세스 상태
- 프로세스는 여러 상태를 거치며 실행됨
생성 상태 (new)
- 프로세스를 생성 중인 상태
- 이제 막 메모리에 적재되어 PCB를 할당받은 상태
- 생성 상태를 거쳐 실행할 준비가 완료된 프로세스는 곧바로 실행되지 않고 준비 상태가 되어 CPU 할당을 기다림
준비 상태 (ready)
- 당장이라도 CPU를 할당받아 실행할 수 있지만, 아직 차례가 아니라 기다리고 있는 상태
실행 상태 (running)
- CPU를 할당받아 실행중인 상태
- 할당된 일정 시간 동안만 CPU를 사용할 수 있음
- 할당된 시간을 모두 사용한다면(타이머 인터럽트 발생) 다시 준비 상태가 되고, 실행 도중 입출력 장치를 사용하여 입출력 장치의 작업이 끝날 때까지 기다려야 한다면 대기 상태가 됨
- 디스패치(dispatch): 준비 상태 → 실행 상태 로 프로세스가 전환되는 것
대기 상태 (blocked)
- 입출력 작업을 요청한 프로세스가 입출력장치의 작업을 기다리는 상태로 완료되면 다시 준비 상태로 CPU 할당을 기다림
종료(terminated)
- 프로세스가 종료된 상태로 운영체제는 PCB와 프로세스가 사용한 메모리를 정리

프로세스 계층 구조
- 프로세스는 실행 도중 시스템 호출을 통해 다른 프로세스를 생성할 수 있음
- 부모 프로세스(Parent process) : 새 프로세스를 생성한 프로세스
- 자식 프로세스(child process) : 부모 프로세스에 의해 생성된 프로세스
- 둘은 각자 다른 PID를 가지고 일부 운영체제에서는 자식 프로세스의 PCB에 부모 프로세스의 PID인 PPID가 기록되기도 함

프로세스 생성 기법
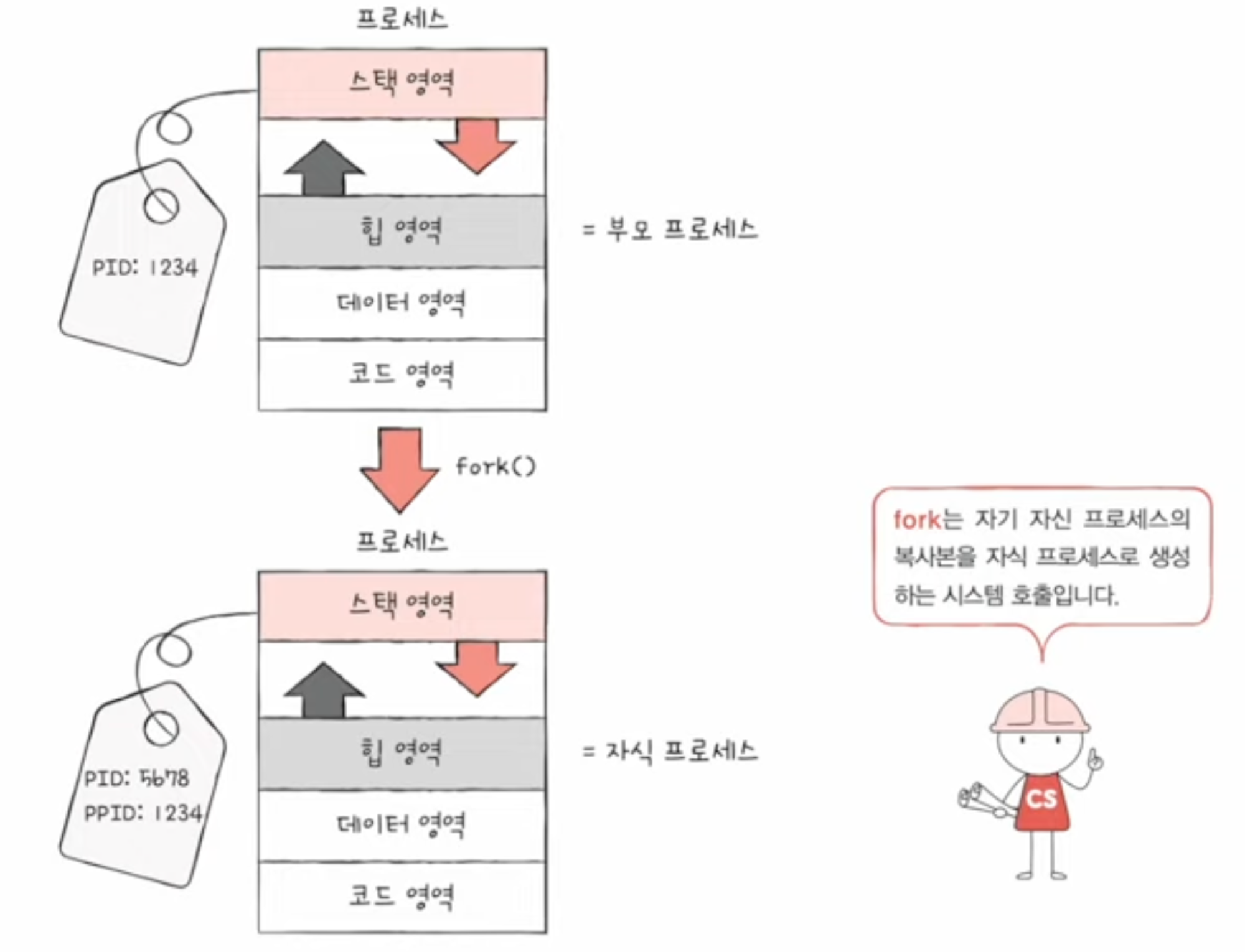
fork: 자기 자신 프로세스의 복사본을 만드는 시스템 호출
- 부모 프로세스는 fork 시스템 호출을 통해 자신의 복사본을 자식 프로세스로 생성
- 부모 프로세스의 자원들 (메모리 내의 내용, 열린 파일 목록) 이 상속됨
- PID값이나 저장된 메모리 위치는 다름
exec: 새로운 프로그램 내용으로 전환하여 실행하는 시스템 호출
- 메모리 공간을 새로운 프로그램으로 덮어씀
- 코드/데이터 영역의 내용이 실행할 프로그램의 내용으로 바뀌고 나머지 영역은 초기화됨

from multiprocessing import Process
import os
def foo():
print('child process', os.getpid())
print('my parent is', os.getppid())
if __name__ == '__main__':
print('parent process', os.getpid())
child = Process(target=foo).start()parent process 6488
child process 27724
my parent is 6488
10-3. 스레드(Thread)
프로세스와 스레드
- 전통적인 관점에서 하나의 프로세스는 한번에 하나의 일만 처리 → 단일 스레드 프로세스

- 스레드라는 개념이 도입되면서 하나의 프로세스가 한번에 여러 일을 동시에 처리 → 멀티스레드 프로세스

- 스레드는 프로세스의 자원을 공유함
- 실행에 필요한 최소한의 정보(프로그램 카운터를 포함한 레지스터, 스택)만을 쓰레드마다 가지며 다른 코드를 실행하고 나머지 힙/데이터 영역은 공유
멀티 프로세스와 멀티 스레드
동일한 작업을 수행하는 단일 스레드 프로세스 여러개 실행 vs 하나의 프로세스를 여러 스레드로 실행하면 어떤 차이가?
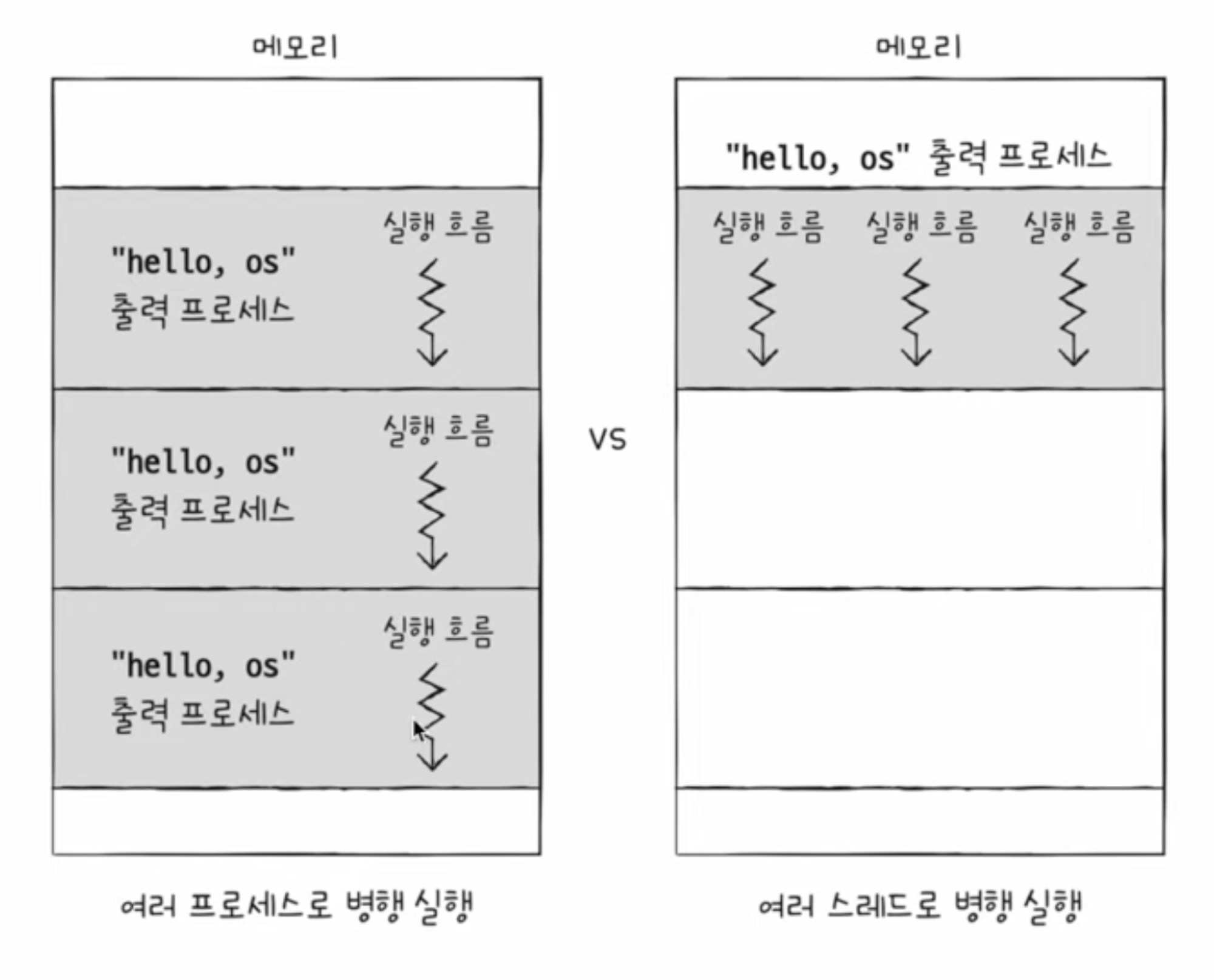
- 프로세스끼리는 기본적으로 자원을 공유하지 않음

- 쓰레드끼리는 같은 프로세스 내 자원을 공유 → 협력과 통신에 유리
- 코드, 데이터, 힙, 파일
- 때로는 쓰레드가 공유하는 자원에서 문제가 발생해서 다른 쓰레드들에도 영향을 미칠 수 있음쓰레드끼리는 같은 프로세스 내 자원을 공유 → 협력과 통신에 유리

import threading
import os
def foo():
print('thread id', threading.get_native_id())
print('process id', os.getpid())
if __name__ == '__main__':
print('process id', os.getpid())
thread1 = threading.Thread(target=foo).start()
thread2 = threading.Thread(target=foo).start()
thread3 = threading.Thread(target=foo).start()process id 11912
thread id 20044
process id 11912
thread id 26056
process id 11912
thread id 21764
process id 11912
- thread의 id는 다르지만 모든 pid는 같음
참고
1. 책 "혼자 공부하는 컴퓨터 구조+운영체제"
2. 유튜브 "혼자 공부하는 컴퓨터 구조 + 운영체제"