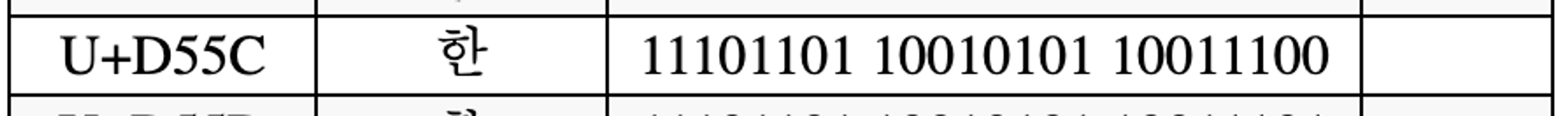본 글은 책 "혼자 공부하는 컴퓨터 구조+운영체제" 의 Chapter 2를 읽고 정리한 내용입니다.
02-1 0과 1로 숫자를 표현하는 방법
정보 단위
- bit: 0과 1을 나타내는 가장 작은 정보 단위
- byte: 8개의 bit를 묶은 단위 ($2^8=256$ 개의 정보를 표현)
- 1 kilobyte: 1000bytes
- 1 gigabyte: 1000 kilobytes
1kB는 1024byte라고 표현하는 것은 잘못된 관습. 1024개를 묶어 표현한 단위는 KiB(키비), MiB, GiB
워드(word) : CPU가 한번에 처리할 수 있는 데이터 크기
- CPU마다 다르지만 워드 크기는 대부분 32비트 아니면 64비트
- 인텔이 x86 CPU는 32비트 워드 CPU, x64 CPU는 64비트 워드 CPU
이진법
수학에서 0과 1만으로 모든 숫자를 표현하는 방법
일상에서 우리는 십진수를 사용하지만 컴퓨터는 2진수를 이해할 수 있기 때문에 변환해서 알려줘야 함
2진수 표기법
ex) 10진수에서 8을 2진수로 표기
- ${1000}_{(2)}$
- 0b1000
이진수의 음수 표현
컴퓨터는 0과 1만 이해할 수 있기 때문에 마이너스 부호를 사용하지 않고 0과 1만으로 음수를 표현해야 함
⇒ 2의 보수를 구해 이 값을 음수로 간주하는 방법 사용
2의 보수 구하는 방법
- 모든 0과 1을 뒤집고 거기에 1을 더한 값
- 예)
- $11_{(2)}$의 보수는 $01_{(2)}$
- $11_{(2)}$ → $00_{(2)}$ → $01_{(2)}$
실제로 2진수 자체만 봐서는 음수인지 양수인지 구별하기 어려워서 컴퓨터 내부에서는 플래그(Flag)라는 부가정보를 사용
16진법
2진수만으로 숫자를 표현하기에 숫자의 길이가 너무 길어진다는 단점이 있음.
⇒ 16진법 사용
표기법 (10진수 15을 16진수로 표기)
- ${15}_{(16)}$
- 0x15
굳이 16진수를 사용하는 이유는 2진수와 16진수 간의 변환이 쉽기 때문
16진수 → 2진수
$1A2B_{(16)}$
⇒ 0001 1010 0010 1011
2진수 → 16진수
$11010101_{(2)}$
⇒ $D5_{(16)}$
02-2. 0과 1로 문자를 표현하는 방법
문자 집합과 인코딩
문자집합 : 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
문자 인코딩 : 문자 집합에 속한 문자를 0과 1로 변환하는 과정
문자 디코딩 : 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
아스키코드
- ASCII: American Standard Code for Information Interchange
- 문자집합 중 하나로 영어 알파벳과 아라비아 숫자, 일부 특수 문자를 포함
- 문자들은 각각 7비트로 표현되는데 $2^7=128$ 개의 문자 표현 가능
- 실제로는 8비트로 표현되지만 1비트는 parity bit 라고 불리는 오류 검출을 위해 사용됨
아스키 코드 표

아스키 코드표를 이용해 표현하고자 하는 문자를 0과 1로 표현할 수 있음
하지만 128개의 문자밖에 표현하지 못하고 특히 한글을 포함한 영어권 외의 나라들은 자신들의 언어를 0과 1로 표현할 수 없음
⇒ EUC-KR 인코딩 등장
EUC-KR
한글은 초성, 중성, 종성의 조합으로 이루어져 있어 2가지 인코딩 방식 존재

- 한글 완성형 인코딩: 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식
- 한글 조합형 인코딩: 초성, 중성, 종성 각각을 위한 비트열을 할당하여 조합으로 하나의 글자 코드를 완성하는 인코딩 방식
EUC-KR은 완성형 인코딩 방식으로 2바이트 크기의 코드를 부여
EX) ‘가’ 는 b0a0으로 표현되는데 2진수로 변환해보면 1011 0000 1010 0000 으로 16bits → 2바이트
EUC-KR 코드표 (일부)

총 2350개 정도의 한글 단어를 표현할 수 있음
- 아스키 코드보다 표현할 수 있는 문자가 많아졌지만 모든 한글 조합을 표현할 수 있을 정도로 많은 양은 아님
- 쀍, 쀓 믜 같은 글자는 EUC-KR로 표현할 수 없음
⇒ EUC-KR의 확장된 버전으로 CP949 가 등장했고 8822자가 추가됨
유니코드와 UTF-8
유니코드 : EUC-KR보다 훨씬 다양한 한글을 포함하며 대부분 나라의 문자, 특수 문자, 이모티콘까지도 코드로 표현할 수 있는 통일된 문자집합
유니코드 문자집합
https://www.unicode.org/charts/PDF/UAC00.pdf
“한”과 “글”이라는 단어를 찾아보면,
- 한: $D55C_{(16)}$
- 글: $AE00_{(16)}$
아스키코드나 EUC-KR과 다르게 문자집합에서 찾은 고유한 값을 다시 인코딩
- UTF-8, UTF-16, UTF-32등이 있음 (Unicode Transformation Format)
- UTF-8 이 가장 대중적
UTF-8
- 통상 1바이트에서 4바이트까지의 인코딩 결과를 만들어냄
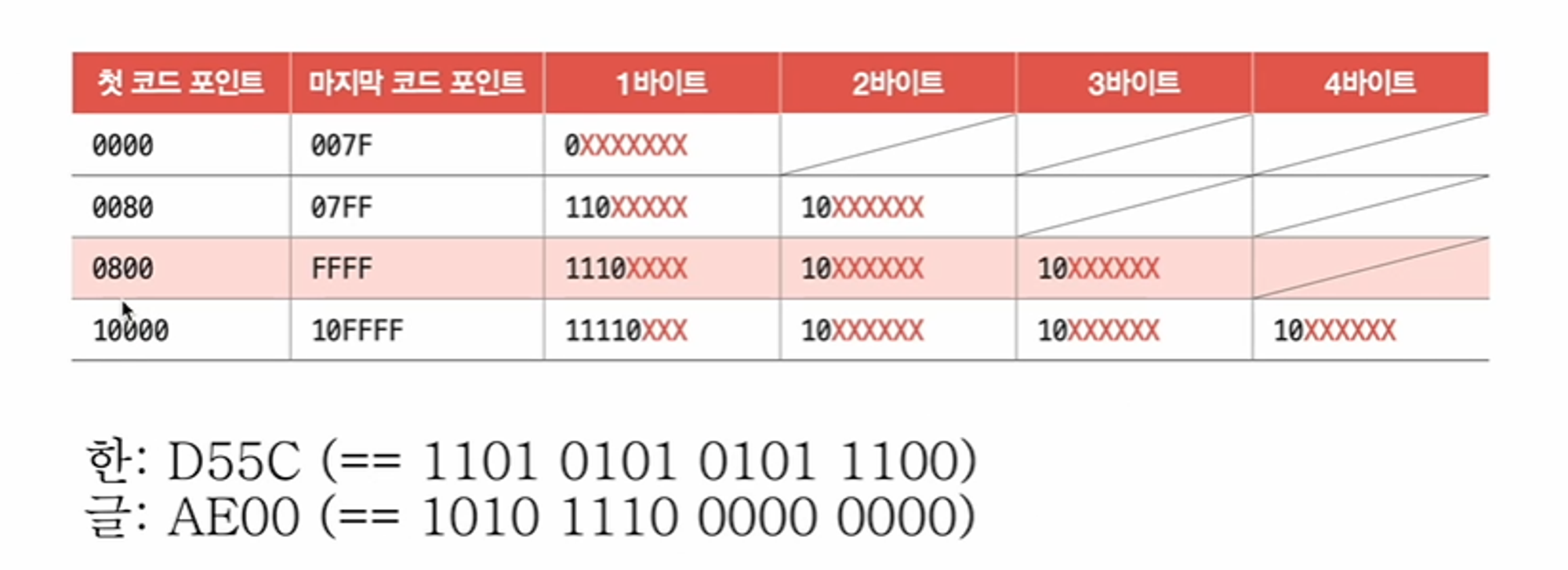
- 첫 코드 포인트와 마지막 코드 포인트 값의 범위를 통해 인코딩된 글자가 몇바이트로 구성되는지 알 수 있음
- “한”과 “글”의 유니코드 값은 각각 D55C, AE00으로 0800~FFFF 사이에 속한다. 그러므로 각각 3바이트로 표현될 수 있음
- D55C는 1101 0101 0101 1100 으로 이를 위에 X로 표시된 자리수에 순차적으로 넣어주면 된다
- 한: 11101101 10010101 10011100