안녕하세요.
인프런에서 파이썬 머신러닝 완벽 가이드 를 들으면서 알게된 내용들에 대해 간단히 글을 쓰려고 합니다.
데이터 셋 파일(보통 .csv) 읽어서 Train, Test 용으로 데이터를 나누기 위해 train_test_split() 메소드를 사용하는데요,
이 때 메소드의 파라미터 중 stratify 가 보이는데 의미와 역할에 대해 정리합니다.
Scikit-Learn의 공식 홈페이지에 가보면 train_test_split() 에 대해 자세히 알 수 있는데요,

stratify 파라미터에 대해서는 User Guide 링크로 대체해서 아래와 같이 설명하고 있습니다.

ensure that relative class frequencies is appoximately preserved in each train and validation fold.
간단히 예를 들어서 설명해보겠습니다.
아래 그림은 하나의 통에 파란색공 4개, 빨간색공 4개가 담겨 있는 모습입니다.
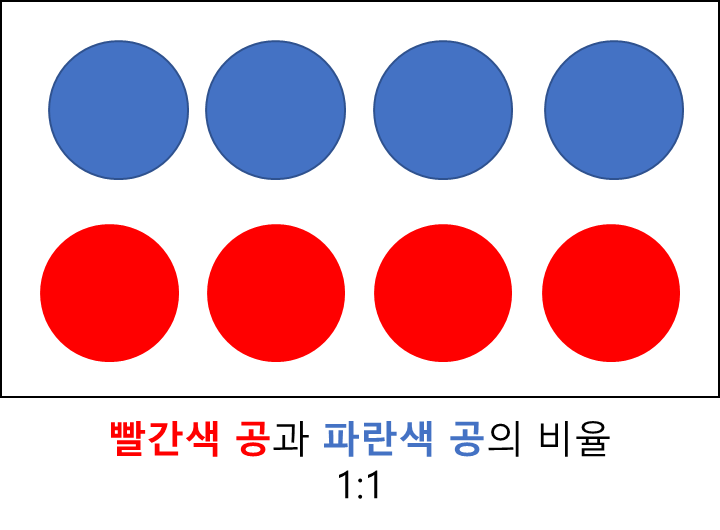
여기서 공을 4개씩 꺼내서 2개의 통으로 나눈다고 가정해보겠습니다. 그러면 같은 색의 공들이 같은 통에 담길 수도 있고,

아래 그림처럼 각 통에 빨간색 공 2개, 파란색 공 2개가 담길 수도 있습니다.

이 경우에는 처음 하나의 통에 담겨있을 때와 마찬가지로 파란색공과 빨간색 공 개수의 비율이 1:1입니다.
이러한 방법을 통계학에서는 Stratified sampling 이라고 합니다.
다시 돌아가서 train_test_split() 함수에서 stratify 파라미터는 데이터를 나누기 전 데이터들의 비율을 나눈 후에도 유지할 것인지를 정하는 파라미터입니다.
극단적으로 [그림 2]와 같이 하나의 그룹(통)에 한 종류의 데이터(공)만 담긴 상태에서 그 데이터만을 이용해 Machine Learning 모델을 학습시키게 되면, 처음보는 종류의 데이터에 대해서는 예측할 수 없는 문제가 발생하게 됩니다.
코드
위의 내용을 강의에서 사용한 피마 인디언 당뇨병 예측 데이터를 이용해 코드로 설명해보겠습니다.
(데이터에서 'Outcome' 이름의 컬럼이 label 컬럼입니다.)
dataset_path = 'datasets/diabetes.csv'
df = pd.read_csv(dataset_path)
X = df.drop('Outcome', axis=1)
y = df['Outcome']
print(f"Outcome 컬럼의 value_counts()결과: \n {y.value_counts()}")
# Outcome 컬럼의 value_counts()결과:
# 0 500
# 1 268
# Name: Outcome, dtype: int64Outcome 컬럼은 0은 500개, 1은 268개로 이루어져있습니다.
(비율: 500/268 = 1.86)
train_test_split 함수를 사용하면 Outcome 컬럼은 아래 코드에서 y_train, y_test 2개의 집단으로 나뉘게 됩니다.
1) stratify 파라미터가 None인 경우 (즉, 위의 500:268 비율을 유지하지 않고 데이터를 나누는 경우)
from sklearn.model_selection import train_test_split
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
print(f"y_train 의 value_counts()결과: \n {y_train.value_counts()}")
# y_train 의 value_counts()결과:
# 0 393
# 1 221
print(f"y_test 의 value_counts()결과: \n {y_test.value_counts()}")
# y_test 의 value_counts()결과:
# 0 107
# 1 47위의 결과를 보시면 y_train과 y_test의 0과 1의 비율은 각각
393/221 = 1.77, 107/47 = 2.27
로 Outcome 컬럼의 0과 1이 비율인 1.86과 같지 않습니다.
2) stratify 파라미터에 Outcome 컬럼을 넣어주는 경우 (즉, 500:268 비율을 유지하고 데이터를 나누는 경우)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
print(f"y_train 의 value_counts()결과: \n {y_train.value_counts()}")
# y_train 의 value_counts()결과:
# 0 400
# 1 214
print(f"y_test 의 value_counts()결과: \n {y_test.value_counts()}")
# y_test 의 value_counts()결과:
# 0 100
# 1 54위의 결과를 보시면 y_train과 y_test의 0과 1의 비율은 각각
400/214 = 1.86, 100/54 = 약 1.86
로 Outcome 컬럼의 0과 1이 비율인 1.86을 유지하고 있습니다.
감사합니다.